2022-07-03
term: 2B
Software Engineering Principles, taken in Spring 2019.
meta
Software Engineering: collection of principles and practices, techniques, processes, tools… that aim to improve software quality, dev productivity, scalability to larger systems, evolvability, more hot words here…
website: student.cs.uwaterloo.ca/~cs247
personel
- Rob Hackman: r2hackman@uwaterloo.ca, Monday 3:30-5:00 PM office hours DC 2128
- Raghav Sethi: cs247@uwaterloo.ca, MC 4065
marks
- Assignments (5% x 3) : 1 late chance
- Project (8% + 7%) : 1 late chance
- Midterm (20%) June 27th, 2019. 4:30 to 6:20 PM.
- Final (50%)
Course Overview
- software engineering principles
- adt (abstract data types)
- defining the rational class
- rvalues and lvalues
- defining the linked list adt
- summarizing the big 5
- invariants
- defining the linked list adt pt 2 : iterator needed!
- the iterator pattern
- entity & value adt
- defining the license plate adt
- virtual functions and defining books
- defining a chess board
- observer pattern
- uml diagrams
- inheritance levels in c++
- vectors in c++
- error handling
- exception safety
- pointer to implementation (pImpl) idiom
- the decorator pattern
- the strategy pattern
- templates (post midterm)
- simplified shared_ptr with templates
- variadic templates
- template meta programming
- MISSING SOME SLIDES HERE
- how to tell the client what the implementation do, and how to use it
- specifying derivations
- derived classes
- checking preconditions
- oop design principles
- oop design principles: coupling and cohesion
- oop design principles: open closed principle
- law of demeter - example, is this substitutable??
- double dispatch (the visitor pattern)
- c++ cast
- multiple inheritance
- virtual inheritance
- refactoring
- the stl algorithm library
- lambda functions in c++
- the singleton (anti) pattern
- constexpr
---
software engineering principles
Language: c++
c vs c++ : why don’t we use c for OOP?
c can do OOP, but:
- doesn’t support inheritance naturally (quirk of c)
- can’t control scope (c has no namespace, c++ uses
::to choose scope) - structs only that are “default constructed”, but can’t define/implement ctors
- variables need to be allocated and initialized (you need to malloc and free yourself, very inconvenient)
Hence c isn’t as well suited for OOP as c++.
adt (abstract data types)
Abstract data types are user-defined types that bundles together: ranges of valid values or data and functions and operations for those values.
ADTs are a means to an end (tool), the client code helps define the ADT’s functionality and only needs to be aware of the interface of the ADT (not the implementation).
Abstracts are the idea of complex data.
- i.e. client has tree, that is internally self balanced, but client doesn’t need to know
- i.e. map works, but hashing function/runtime efficiency is hidden
Use the compiler or definition to enforce the proper usage/rules of the ADT. i.e. valid ranges of data
example:
#include <iostream>
using namespace std;
int main(){
cout << "enter rational number (a/b) : ";
//need to define default ctor for Rational class
Rational r,p,q;
//overload >> operator w istream&, return Rational&
//needs to be ref because:
//1. modify original value later
//2. iostream can't be copied, won't compile by value
cin >> r >> q;
//overload + operator with Rationals, return by value
//needs to be by value because new object result
//if by ref: heap allocate rational ref, manually delete later???
//no. that's a mem leak.
p = q + r;
//overload << operator w ostream, return const Rational&
// const ref optimized by compiler, faster copy
cout << q/r;
//define copy ctor for rational adt
Rational z{q};
}
Things to define:
- the default ctor for the Rational class
- overload », «, +, /
- define the copy ctor
does an adt have to be a class?
nope.
ADT is a concept, not an implementation. The data structure is an implementation of an ADT. For example, we can also implement an ADT with a struct.
why use c++ classes?
- Construction is guaranteed*
- Destruction is guaranteed*
- Can enforce legal value ranges using field visibility (encapsulation aka public, private, protected)
*on the stack: not guaranteed if you create an object on the heap aka new and delete
encapsulation is a language mechanism to restrict access to some objects’ components, facilitate bundling of data
On the other hand, c structs:
- can’t define member functions (in c, functions are globals where the object is passed in as a parameter, no this, aka functions don’t belong to structs)
- can’t make ctors and dtors, only stick with what’s available. Also need to know the size to malloc, can potentially disallow self-referencing classes (which is bad design anyways, you should use pointers)
side note: when you pass an non-pointer object, you pass around a lot more memory than you need. The size of struct/class is at least the sum of the size of all its fields (compiler will set extra variables like vtables to store address of member? functions…), so a pointer is relatively much smaller and is better design.
do you always have to define a default constructor?
nope.
Only if there are appropriate defaults to set. i.e. default birthday????? doesn’t make sense.
The original default constructor is implicitly defined. BUT Disappears when you define any constructor.
side note: similarly the default dtor is implicitly defined and disappears when you define a dtor, but you really just need one dtor so lol it’s ok
why use MIL (member initialization list)?
Short answer: used to init data members/fields
example: class::class(param) : my_field(param) {}
Need to use if fields or superclass doesn’t have a default constructor. For example, if a superclass has a constructor with params, it loses the default constructor. Then, you would need to specify the constructor using the member initialization list.
object construction process in c++
- allocate space for the new object
- initialize the superclass if needed: will use the default ctor unless MIL tells compiler which ctor to use based on function signature (aka params)
- initialize all object members/fields using ctor in order of declaration in the header, unless told to use other ctor and initialize all primitive fields (PoD)
- new object’s ctor’s body code runs
Note that object members are created in step 3, but if you reconstruct objects in the body, objects will be created twice
class A {
public:
A(){};
};
class B {
A a;
//will call A's default ctor, creates throwaway A
//before body of ctor also creates an A
public:
B(){
a = A();
};
};
What if the superclass’ default constructor does exist? A is constructed twice because once before for all member objects, and once when you get into the body then is move assigned/copied to another “A” object into a, in line a = A();.
If you don’t initialize properly (aka don’t use the MIL), your superclass gets default constructed and then you waste that time because you’ll just overwrite that default constructor in the body again. THIS IS VRY INEFFICIENT AND SLOW >:(
aka you created an object you didn’t want, just to overwrite it again in the object’s constructor. Just initialize A right the first time… don’t initialize an object multiple times.
exaggerated example:
class Foo {
public:
Foo() : size{large}, x{new int[large]};
}
class Bar {
Foo f;
#ifdef FAST
//do the quick things
#else
Bar(size_t x){
//first construct f with large crap
//unfortunately initialized to random values
Foo otherF{x}; //fast way,
// but ctor body runs after all MIL object construction are done
// reassign a shit ton of values copying things over...
f = otherF;
//time consuming :(
}
}
defining the rational class
class Rational {
public:
Rational();
Rational(int num, int denum) throw (char const*);
explicit Rational(int num);
}
throw (char const*) tells the compiler that the Rational(int, int) ctor may have an implementation of exception catching, might trigger/throw of type char const*
- the usage of Rational(int, int) must either be in a try-catch, or it’s function signature also needs to say
throw, and if needed, must throw error of of the same type that is specified - as opposed to
noexceptwhich promises not to throw: the compiler will optimize (i.e. likeconst)
explicit keyword:
- specifier for single parameter ctors that disallows the compiler from using that constructor to implicitly cast types from the param
- disables implicit type conversions
- use to avoid accidental construction especially in parameter lists
class Foo {
public:
/*explicit*/ Foo (int x) {};
}
void doBar(Foo f){
//...
}
In this case: without the keyword explicit, doBar(42) would construct Foo(42) as its param since doBar() only takes in Foo params, because it will try to convert 42 into a Foo somehow
This isn’t always a mistake, but in cases it is.
With explicit on Foo’s constructor, doBar(Foo(42)) would be the only valid usage, and doBar(42) won’t compile.
Helps to catch programmer mistakes.
accessors and mutators
Accessors: will not change state of object, only returns, getter
Mutators: can change content of class, setter, ideally checks client-provided values, may throw error if invalid, can implement exceptions to guarantee
constructor with MIL
Construction should only happens once. In the following order, whichever does it first.
- MIL
- Class members
- Ctor body
MIL is only a ctor thing, not applicable to other functions.
attempt 1
class Rational{
int num_, denum_;
public:
Rational() : num_(0), denum_(0) {};
Rational(int num_) : num_(0), denum_(0) {};
Rational(int num_, int denum_) : num_(0), denum_(0) {};
}
Too many constructors, gross. We can replace all that with a ctor with default parameters.
attempt 2 with default parameters
compiler will translate Rational(int num_ = 0, int denum_ = 0) : num_(num), denum_(denum) {}; into one with n param, n-1 param, …. 0 param, decreasing from the right.
Order is rightmost/end for defaults, and non-defaults must be on the left/front so that there isn’t any ambiguity.
attempt 2
class Rational{
int num_, denum_;
public:
Rational(int num_ = 0, int denum_ = 0) : num_(num), denum_(denum) {};
// default parameters must be trailing
}
In this example, Rational will never have a ctor with just a denum_ and no num_. It will have both because both are declared as defaults.
Notice that foo(int x, int y=s, int z) is NOT ok, we can’t put non-default z as the last. Will becomes ambiguous, not formal language, will have multiple meanings…
hence: Default params must be trailing!
In other words, default arguments MUST only appear in the function declaration. Once the default is used in the function call, all next arguments in call must be defaults else ambiguous (the compiler doesn’t see the parameter names)
i.e.
Rational(int, int = 1){}
// above is equivalent to declaring below
Rational(int, int){}
Rational(int) { int = 1; }
copy constructor
Rational(const Rational& r) : num_(r.num), denum_(r.denum) {};
The curly copies. Rational B{A} where A is an existing Rational object, into the new Rational B.
When you can, always use const.
& because if it’s by value, it’ll look for that Object’s copy ctor, which is what you’re currently defining
Generally, you should always use:
- a const reference param whenever you can
- a reference param because it’s still quicc !!
- copying by value because you don’t want to change the original (last resort) (good practice, follow this hierarchy)
Doesn’t make too much of a difference for primitives.
overloads on operators
Overloading because even though the function names are the same, they take in different param types (function signature is different, can be guaranteed to call the correct one because Rational is a newly defined class).
Note: Different return type cannot validate a function overload.
This is a BAD overload that compiler will cry about:
int foo();
Rational foo();
Hence, changing the return type and not the parameter types would not count as an overload. It must be in the parameters.
You can define operators (functions with names as symbols) with custom functionality. The only guideline is the function name: operator concat function_symbol.
Operator functions are special functions where instead of calling the function name, you just call the symbol in most cases (has exceptions).
i.e. the copy assignment operator is an overload on the “=” operator
copy assignment operator
Rational& operator=(const Rational& other){
num_ = other.num_;
denum_ = other.denum_;
return *this; //dereference this, which is a ptr
}
Why is the return “this” ? To be able to chain copy assignments i.e. a = b = c = d = e; The execution order would be d = e; c = d; b = c; a = b… nested from the right.
why Rational& ? and subsequently return *this;
- We could return a copy by constructing a new Rational, but when we exit the end of the function/the scope, the returned new constructed Rational will be destructed.
- Something on the heap exists in the global scope, so can be dereferenced and returned (return by reference).
- (sidenote: passing/returning by value calls the copy constructor.)
- (clarification: returning by reference doesn’t actually return just the address, it returns the object at that address, but not as a copy, like that literal original teleported object.)
- Also because code like
(p=a)++exists.- Order of operation:
ais assigned top, which is an l-valueoperator=()returnspas*this, which is incremented
- Order of operation:
The first param is implicitly the Rational pointed by the this pointer for operators. Basically def func(self, param1): equivalent of Python, but you don’t need to explicitly state for c++.
operator+: between 2 Rationals
attempt 1 : as a non-member function
Non-member function are outside of the class and don’t have access to private member fields, unless it’s a friend.
Here, the implications of a non-member function mean that operator+() has no access to numerator or denominator (all private fields/members). Thus, must tell the Rational class that this function is a friend, so that we can access all the Rational’s private fields.
Note: we can mark a function as friend multiple times/places.
Rational operator+(const Rational& LHS, const Rational& RHS) {
//const ref for speed optimization since no modifications
//is friend so we can access private fields
return Rational{LHS.num_ * RHS.denum_ + RHS.num_, RHS.num_ * LS.denum_, denum_ * RHS.denum_}
}
Here, we don’t want to release the information of the private fields to the client, hence declare operator+() as a friend inside the class:
friend Rational operator+(const Rational&, const Rational&);
Note that argument names are not needed in function signature.
Recall that you can declare things many times, but can only define things once.
Drawbacks of attempt 1:
- too many friends
- 2 params
attempt 2 : member function
Rational operator+(const Rational& RHS) {
//const ref (2nd term) for speed optimization
return Rational{num_ * RHS.denum_ + RHS.num_ * denum_, denum_ * RHS.denum_}
};
Only uses one param, because function is within class. Hence the first param is this. Note that because there isn’t a conflict with variable names, we can omit the this->varname. Behaves the same anyways.
Difference from attempt 1:
- doesn’t need to be a friend because is member
- 1 param!
Generally you should always define member functions as const.
operator+: between Rational and an int
We also need to be able to add an int to a Rational. Function overloading: same function name, different parameter types.
Rational operator+(int x) {
return Rational{x * denum_ + num_, denum_}
};
Currently, addition between a Rational and an Int is not fully functional: not symmetric because we’re missing int + Rational.
Rational p = r + 7; is defined: r is this when + is called.
Rational p = 7 + ris not defined: 7 is this, but no int operator+(const Rational&) defined.
Because of the way the + is called, we can’t have the reverse to be a member function because wherever int is implemented, we don’t have access to modify operations of int. Hence operator+ on an int and a Rational in that order needs to be defined as a non-member function.
We define this function as a friend, even if int doesn’t have private values, Rational does, so it needs to be a friend in the Rational class.
friend Rational operator+(int x, const Rational&);
Implementation:
Rational operator+(int x, const Rational& r){
return r + x;
//which calls operator+(int x)
//which is implemented
}
Now int + Rational will call Rational operator+(int x, const Rational& r).
Addition now works in both orders.
operator/
Exactly the same idea as operator+, just different math.
operator«: between ostream and a Rational
- ostream passed in first to be the
thisequivalent. - can’t copy ostream (implementation of ostream in c++ prevents copying), hence passed by ref
- need chaining functionality i.e
cout << a << p << r;, hence return ostream - return ostream by ref because you can’t return an ostream copy
- friend because ostream needs access to privates (num_, denum_) in implementation
friend ostream& operator<< (ostream&, Rational&);
Generally, unless specified or by common sense, your implementation should not have an endl; because:
- risk of double
endlon the user’s side - prevents chaining
ostream& operator<< (ostream& out, const Rational& r){
return out << r.num_ << "/" << r.denum_ ;
}
operator»: between istream and a Rational
Inside the class:
friend istream& operator>> (istream&, Rational&);
Implementation (not a member function):
istream& operator>> (istream& in, Rational& r){
return in >> r.num_ >> r.denum_;
}
- needs to also be chained i.e
cin >> a >> p >> r;hence returning the istream reference is a good idea - remember that the ostream and istream can’t be member functions: when called, the order is
cin >> xorcout << x, and cin/cout are the first parameters. We have no access to istream and ostream. You literally can’t even if you try to implement it the other way.
in general, prefer to design non-member, non-friend functions
Why: want to limit the access of privates as much as possible, and implement setters and getters instead. Friendship in c++ must be used carefully.
i.e. if heap, don’t get all, just be able to get root or something. (use accessors and mutators)
Friendship is not commutative unless you friend both sides.
rvalues and lvalues
tl;dr:
- l values are any data that is guaranteed to have a memory address (a location in the program)
- is anything that isn’t temporary; it exists past the end of that statement
- the result of
5 + 3is clearly not an l value, it’s in the register -
- r values
- in general, the result of expressions is
-
Foo genFoo(){ Foo f{ ... } ... return f; }At the point of
return f;, f is deemed to be an rvalue because it’s going to die (exists in the function stack frame, which will be popped). The result itself of an expression,genFoo(), is an rvalue (even though it really gets move constructed). With no compiler optimization, there will be 2 move constructor calls:-
Foo myFoo = genFoo(); -
one to construct the return value of genFoo()
- one to move construct myFoo from the return value, unless there are compiler optimization, this second construct isn’t done and the compiler moves it directly to myFoo, aka copy elision
-
R-Value (return value)
The return value of foo() is guaranteed to not exist after the foo() statement. R-values in c++ are temporary values: lives in a register without an address.
R-values only appear on the right hand side.
Node foo() {
Node p ....
return p;
}
int main() {
Node n = foo();
}
Note here, you can’t call bar() on an r-value, because its type is an l-value reference of 5+3. Since 5+3 is stored in a register temporarily, no address so none to pass to bar().
void bar(int &x){
... some assignment command idk
}
int main(){
bar(5+3); //doesn't work
}
UNLESS 5+3 is const: the compiler will allow it by potentially creating a temporary address. Since it’s const, the compiler knows that you won’t mutate it, so the address can be created.
You can’t bind an r-value to an l-value.
L-Value (lifetime value)
The opposite of an r-value, it’s guaranteed to have a memory address and has a lifespan past the individual statement.
L-values can appear on the left hand side, except const l-value (can’t be assigned).
Foo doFoo(Foo &&f){
}
int main(int argc, char const *argv[])
{
Foo f;
doFoo()
return 0;
}
defining the linked list adt
We want the client to do: Node n{3,new Node{2, new Node{}}};, which makes a linked list of 3->2->1.
Also needs this functionality:
Node p{n};
p.next->data = 20;
cout << p; //expected: 3, 20, 1
cout << n; //expected: 3, 2, 1
Tangent: what’s a string? it’s an array of char even in C++, just wrapped in a handy String class.
constructors
copy constructor with deep copy
We want deep copy, implemented using recursion. (Not going to worry about encapsulation rn).
Why did we want deep copying? Lists need to be distinct. But is there any duplication? Nope, it’s guaranteed that the original copy will die after the line of creation. (r-value)
class Node {
public:
int data_;
Node *next_;
//constructor
Node (int data, Node *next_ = nullptr);
//deep copy constructor with recursion
Node (const Node& other) :
data {other.data}, next {other.next? new Node{*other.next} : nullptr};
//base case == next is nullptr, and normal case
}
Knowing r-values, we actually don’t need to deep copy the list.
move constructor with shallow copy
sidenote: Node (Node &&o) is not a reference to a reference, it’s the ref of an r-value.
We have temporaries to copy (i.e. move constructor) but we don’t want to deep copy because that’s slow. (And don’t care for deep copying).
How else can we move it? Shallow copying the pointer.
Node (Node &&o): next{o.next}, data{o.data}{
o.next = nullptr;
}
When you move o.next, it immediately dies and frees its list, so we reset o.next to a nullptr so that it doesn’t deallocate the list we just stole with the MIL. So instead, it’ll become a dangling pointer, it doesn’t delete the list immediately.
NOTE: that o is a reference to an r-value. But o as a parameter is not an r-value: o.data is an l-value.
what is data{o.data} ??? We don’t want to call the copy constructor because o is about to die and we don’t want to deep copy it. Let’s move o.
data{o.data} calls the string’s copy constructor. BUT we want to treat this thing as an r-value, because we know that it’s an r-value.
Solution: std::move overrides the compiler’s decision, swaps it like an r-value.
using std::move;
Node (Node &&o): next{o.next}, data{o.data}{
o.next = nullptr;
}
Node::Node(Node &&other) : data_{std::move(other.data_)}, next{other.next} {
other.next = nullptr;
}
a little bit like casting.
copy assignment operator
attempt 1
Node& operator= (const Node &other){
data = other.data;
delete next;
next = new Node{other.next} //BUT new might fail
return this;
}
Reasons why new would fail:
- run out of memory
- OS tells the process “no.!” i.e. if your OS limits your program’s resource
What’s wrong if new fails?? It’s not NULL, it’s a dangling pointer. If you dereference a dangling pointer, you won’t segfault, but you’ll get garbage instead :(
If new fails, we want to ensure that our Node doesn’t get mutated. How? Call new first.
attempt 2
Node& operator= (const Node &other){
Node &tmp = new Node{other};
data = other.data;
delete next;
next = tmp; //there is no tmp when you delete next = tmp
return this;
}
A failed new could be handled by exceptions now. Better to write this way.
First copy, then delete, also solves another issue. What happens with :
Node n ....;
n = n;
Self-assignment, assigning this object to reference. When you delete next, you’re freeing the memory for the next pointer
When you try to deep copy other’s next pointer, you
Trying to reference a dangling pointer is a memory error. The copy and swap idiom solves this issue, but you’re still doing a deep copy unnecessarily.
Solution: if self-assignment, return this. Two addresses are the same, if they reside in the same location in memory. Check for self-assignment by if (this == &other) return *this;
attempt 3: the copy and swap idiom
Node& operator= (const Node &other){
Node tmp{other};
using std::swap;
swap(data,other.data);
swap(next,other.next);
return *this;
}
move assignment operator
attempt 1
Node& operator= (Node && other){
data = other.data;
next = other.next;
}
This would fail test cases. Once other goes out of scope, the list gets deleted.
attempt 2
Node& operator= (Node && other){
data = other.data;
delete next;
next = other.next;
}
Memory leaks. Better than the first attempt at least.
attempt 3
#include <utility>
Node& operator= (Node && other){
using std::swap;
//within this scope, swap is from std
swap(data,other.data);
swap(next,other.next);
return *this;
}
Why swap instead of assigning? Easier to implement, more memory efficient than copying. We reused swap, might as well create a private swapping function.
destructor (memory leak handling)
~Node() { delete next; }
Explicitly calling the destructor for next isn’t enough. How to deallocate the next Node?
Every time there is a new, there must be an equal and opposite delete.
When you delete a heap-allocate object, it goes out of scope and gets destructed. The idea of recursion calls each element next on the list, which handles the rest of the nodes.
At the end, delete the nullptr and then we’re good.
closing notes of the linked list
Client can break rules…
Node n {3, new Node{2, nullptr}}
{
Node p{4, &n}
}
Error with constructing Node p
p will go out of scope when exiting the code block, and runs p’s destructor, which calls delete on the next pointer. BUT!!! the next pointer was a stack-allocated address, can’t call delete on that! Even if n is heap-allocated, then n is still going to end up as a dangling pointer, which is not good behavior.
Hence, we have some rules that we must uphold so that our ADT can work properly. Rules are a result of some assumptions we made when writing the code.
invariants
Invariant: assumptions or properties that must hold for the code to work properly. Assumption example: delete next; in destructor, (either assume that object is always a heap-allocate object, or it’s never a heap-allocated object).
You cannot trust that your client code will uphold your invariants. Also, they shouldn’t have to. Don’t expect the client to memorize all your rules.
summarizing the big 5
- copy constructor
- move constructor
- copy assignment operator (cao)
- move assignment operator (mao)
- destructor.
General rule of thumb: all or nothing
If you have to provide a user-defined definition for one of these above, you should define all of them.
When to define?
When you have a resource to maintain/manage (i.e. memory, socket, file pointer…)
built-in default behaviour
- copy constructor: copies all values and copy constructs all fields (shallow copy, bad for pointers because you only copy the value, hence have multiple pointer pointing to the same space, and deletion will leave other pointers pointing to garbage).
//To delete this ctor, you're going to have to explicitly define it as `= 0;` //Defining the copy constructor will not delete the default move constructor //may be both lies - move constructor: move all values, shallow move bad for pointers.
- copy assignment operator (cao): copies all fields and copy assigns all fields
- move assignment operator (mao): move all fields and move assigns all fields
//Note that if the MAO is defined, you lose the default CAO - destructor.
copy constructor
- Uses copy ctor when you construct an object with another object of the same type.
- When a function receives an object parameter by value
- when a function returns a value except when a move constructor is defined (because then the move ctor is used to return a value)
If case 1, 2 use an r-value as the argument, then the move ctor is used as well.
The compiler provides built-in implementations of ctors: the copy ctor executes a byte-wise copying all plain old data PoD (int, char, bool, all basic types, pure structures) and copy constructs all object fields.
Doing a byte-wise copy on pointers is insufficient, because you’d copy the pointer’s address and not make a new object. Hence copy ctor was redefined for the linkedin.
The built-in move constructor also does byte-wise
The copy assignment operator byte-wise copying all PoD, and copy assigns all object fields.
- If you define the CAO, you lose the built-in MAO.
- If you define the MAO, you lose the built-in CAO.
You’ll lose efficiency if you only define the CAO, it will never use MAO because it’s not defined.
- If you define the copy ctor, you lose the built-in move ctor.
- NOT VICE VERSA
destructor
Use destructor when an object goes out of scope. If heap allocated, then when object’s delete is called. If stack allocated (statically allocated), when their enclosing scope ends.
class B {};
class A {
B b;
}
A *p = new A;
delete p;
Object A pointed by p is dynamically allocated. Object B pointed by p is on the heap (created as part of A), is statically allocated. When *p dies, b dies as well.
invariants
assumptions that must hold true for our code to work properly. It’s hard/impossible to reason about the code without them.
i.e.
- Node assumes ownership of the next Node in order to be able to delete the next Node. In other words, next Node should be a heap-allocated object
- Linked List should not be cyclical
- Node shouldn’t share the next pointer, else improper deletion
- Users should not know of the existence of class Node, they should be given a List class representation to work with, which indirectly exposes nodes
^^^ but currently we have no control over these
Should not be the client’s responsibility to know and uphold the rules. Why can the client break these rules:
There is currently no checks in constructor: this allows the client to select the next pointer (next Node), but we can’t guarantee that clients use them properly.
representation exposure
Allowing the client to use nodes at all is representation exposure. Representation exposure is external access to the implementation of the ADT, meaning that client code can modify the representation directly.
The ADT we want to give to the client is a linked list, not Node pointers. The clients really shouldn’t know how the linked list is implemented (or all the invariants of the implementation).
THEREFORE: we want to encapsulate the implementation logic and hide it from the client
defining the linked list adt pt 2 : iterator needed!
i.e. client usage
List l;
l.push(3).push(2).push(1);
//{1,2,3}
l.ith(i) = 5;
//list.h
class List {
class Node {
//private nested member
//implement as before
}
Node *head;
public:
List() head {nullptr};
List& push(int data);
//Big 5 for lists:
int& ith(int i);
}
//list.cc
List::Node::Node(int data, Node *next) ...
List& List::push(int data) {
head = new Node { data, head };
return *this;
}
Changing the header file: client code needs to recompile
Changing the cc file: client code doesn’t need to recompile???
reference is just part of a type signature
Giving integers by reference
int & List::ith(size_t i) {
Node * node = head;
while ( i > 0 && node){
--i;
node = node->next;
}
return ith->data;
//crashes if node
}
Why is ith() bad??? Look at this client code:
#include <iostream>
using namespace std;
...
list l;
size_t (....)
for (size_t i = 0; i < len; ++i){
out << l.ith(i) << endl
}
ith() takes \(n^2\) to iterate through a list…
We need to give user a similar way to iterate through the lists as they did before, but not expose the representation, and improve on the runtime.
What we want is an iterator:
See client code:
for (thing = beginning of list; thing != end of list; ++thing){
*thing = *thing + 1;
cout << *thing;
}
What helpers/components do we need to implement an iterator??
- get the beginning of list::iterator i.e. list::begin()
- get the end of the list::iterator i.e. list::end()
- be able to increment the list::iterator
- implement the unary star operator (*) dereference operator
- need inequality (and equality is nice to have )
What private data do we want to put in the iterator?
class List {
Node* head;
public:
class Iterator {
Node *curr;
public:
bool operator != (const Iterator&);
Iterator& operator++;
int& operator&();
friend class List;
}
};
//back in the List struct definition
Iterator begin();
Iterator end();
//@list.cc
List::Iterator List::begin() {
return Iterator{head};
}
List::Iterator List::end() {
return Iterator{nullptr};
}
the iterator pattern
(our first design pattern)
The design pattern is a common solution to a common patterns
(…)
entity & value adt
examples
entity: people, planes, runways, bookings, deck, card, player,
value: rational, lists, units of measurement, point, force, birth dates, suit, score
entity
- is an ADT that reflects an entity in the real world
- computer embodiment of a real world entity, literally an object
- object with the same attribute values are NOT equal
- should not allow copying (either via constructor/assignment)
- doesn’t make sense, no longer reflect reality (i.e. if youre cloned that’s a cloning function)
- entities are referred by pointers and references due to the no copying rule
- if necessary, may want to implement a clone
- think before overloading operations for entity adts (aside from the move assignment, and if necessary, the copy assignment)
- prefer to avoid implementing type conversion functions
- operations on an entity should reflect a real-world event
i.e. physical objects, people, records, transactions
value
- just represents some sort of value (i.e. measurements, numeric value, etc…)
- allow copying values
- typically disallow the mutation of individual fields (should start over and create a new object completely)
- allow overloaded operators as necessary, equality is important
i.e. mathematical types, measurements, quantities of money, colour/location/time properties, restricted value sets like postal codes/number ranges
mutable vs immutable objects
mutable object:
- mutable objects change via mutators (
set()) or other functions that act on them
value-based objects are usually not mutable.
immutable object:
- has no mutator
- member functions cannot be overridden (non virtual)
- copy/assignment operations are deep copies
- all data members are private
- all data members are of primitive or immutable types, else
- make a copy of any (mutable) attribute parameter value
- make a copy of any output (mutable) attribute return value
defining the license plate adt
license plate is an adt value is a value, but simplifying
requirements:
- 3 letters followed by a hyphen, followed by 3 numbers
- 4 letters followed by a hyphen, followed by 3 numbers
- vanity plate, any combination of 8 letters or numbers
- default constructor, want to generate the next plate number
- parameterized constructor, string for vanity plates
examples:
- aaaa-0000
- aaaa-0001
operator< for sorting
assumptions:
- plates are issued in order
- vanity plates can’t be duplicates/replace old vanity plate
== we need information about all license places created, and hence, we need some state that is maintained not just within the lifetime of an object, but across the entirely of that class. (i.e. cd)
static member variable
essentially a global variable (that’s how the compiler will implement this), but with some extra context and properties (scope…)
All objects/instances of the same class share the same static variable.
class Foo {
int x;
public:
static int count;
Foo(int x) : x{x} {++count;}
static void
}
can’t define twice, so we need to put the definition in foo.cc can declare things as much as you want
class Foo; //declaration
class Foo; //declaration
class Foo; //declaration
class Foo {}; //definition
foo.cc //implementation
You can write the definition outside of a class, but you would never be able to use it.
int main(){
Foo f{5};
Foo f2{10};
cout << f.count << " " << f2.count << endl;
cout << Foo::count << endl;
Foo f3{7}
f.printCount();
Foo::printCount();
}
we probably also want a helper, to increment our next available
class License Plate {
static std::string nextAvailable;
std::string plateNo;
static void updateAvaliable();
public:
LicensePlate();
LicensePlate(std::String);
Bool op
}
adding a header guard
#ifndef LICENSE_H
#define LICENSE_H
#endif
To avoid files that include files that include headers, hence the headers would be copied twice, which is not good. Remember, the rule is to define only once, but can declare many times.
i.e.
//a.h
#include "b.h"
//main.cc
#include "a.h"
#include "b.h"
When you include, it copies from a.h to main.cc, but a.h also has a copy of b.h. The compiler will complain that of multiple definition compile error. Using #ifndef and #define means if-not-defined, define, which is a header guard.
If you wrap your header with the header guard, then preprocessor will execute checks and only copy if needed. Any subsequent includes will have no effect, when using the header guard.
back to the license plate adt
simplification to ignore vanity plates. So far, we’ll need class LicensePlate, with plateNo, and ctors.
license.h
class LicensePlate; is a forward declaration
class LicensePlate{}; is a definition, and hence needs to be header-guarded.
#ifndef LICENSE_H
#define LICENSE_H
#include <string>
class LicensePlate{
static int fourDigits;
static char charOne, charTwo, charThree;
static void updateNextAvailable();
std::string plateNo
public:
LicensePlate();
LicensePlate(string::string name);
//this is a bad idea
//License(std::string vanityPlate = "");
};
#endif
Why is License(std::string vanityPlate = ""); a bad idea? i.e. if empty string, then not a vanityPlate.
Make things behave as expected! Weird case where the user tries to create a vanity plate with an empty string should return an error, not a normal plate. Compiler should at least complain (if not using exceptions).
Why don’t we write using namespace std in the header as well?? Because it’ll also pull in the namespace into the .cc whenever included. The headers should not enforce which namespace to use.
You should actually NEVER use using namespace ... for header files. Try to include as little as possible.
overloading the input operator
public:
bool operator<(const LicensePlate &other) const;
Declare functions as const whenever possible!
license.cc
As opposed to the header files, include all that you need, even twice. Be thorough.
#include "license.h"
#include <string>
#include <sstream>
using namespace std;
int LicensePlate::fourDigits = 0000;
char LicensePlate::charOne = 'A';
char LicensePlate::charTwo = 'A';
char LicensePlate::charThree = 'A';
void LicensePlate::updateNextAvailable(){
if (fourDigits < 9999){
++fourDigits;
return
} else if (charThree == 'Z'){ //last char
if (charTwo == 'Z'){
++charOne; //assume not Z
charThree = charTwo = 'A';
} else {
++charTwo;
charThree = 'A';
}
fourDigits = 0;
return ;
}
fourDigits = 0;
++charThree;
//build in constructor
return;
}
LicensePlate::LicensePlate(){
//combine all together
//write to io string stream
stringstream ss;
stringstream charStream;
//init and set ss properties
ss << setfill('0') << setw(4);
//combine all these types in one string!
charStream << charOne << charTwo << charThree << "-";
string(charThree);
string numberString;
// will grab the first set of contiguous non whitespace set of num
ss >> numberString;
plateNo = charStream.str() + numberString();
updateNextAvailable();
}
void LicensePlate::nextPlate(){
}
iostreams: use the most suitable one depending on whether you need to input/output…
ISSUE: can copy construct license plates, which doesn’t make sense because license plates are unique. By default, copy ctor exists.
Options:
- define move ctor and operator
- define copy ctor as private functions so that users outside cannot use it
LicensePlace(const LicensePlate&) = delete;LicensePlace &operator=(const LicensePlate&) = delete;gives “use of deleted function” error message
compiling without a main
g++ -std=c++14 -c myfile.cc
-c means to compile only, no linking of code. Will only compile the given inputs into corresponding myfile.o
ex1
This is very important as we need it for separate compilation:
g++ -std=c++14 -c license.ccgiveslicense.og++ -std=c++14 -c main.ccgivesmain.og++ license.o main.o -o myProgramgivesmyProgram
ex2
This compiles both and then links: g++ -std=c++14 main.cc license.cc -o myProgram
changes and recompilation : true dependencies
What happens if I change main.cc? Need to run g++ -std=c++14 -c main.cc and g++ license.o main.o -o myProgram in the first example.
What if license.h changes? Recompiles every .cc file that has a true compilation dependency with license.h. A true compilation dependency includes license.h when compiling the file with the dependency.
If it’s not a true dependency, don’t introduce dependencies by including files, just forward declare:
//a.h
class A{}
//b.h
class A;
class B{
A* a;
//forward decl is enough
//no instantiation
//compiler always know size of ptrs
}
//c.h
#include "a.h"
class C{
A a;
//stores A in C, needs to include
}
//d.h
class A;
class D{
A& a;
//references may not take up space
//compiler implement with ptr
//not actually storing A in D
//no compilation dependency
}
//e.h
#include "a.h"
class E : public A{
//size of class E depends on class A
//true compilation dependency
}
//f.h
class A;
class F{
A myFunction(A a);
//implementation will need to know about A
//but declaration does not require A
}
The goal is to not have to include lots of headers in the header files.
Only include when you absolutely must. Else, if possible, just forward declare. Modularize!
A header (interface) file and its corresponding .cc file (implementation) together is a module.
We want to break programs up into small distinct reusable modules. This means that our program will be split up into many files that we need to compile and link… huge time consuming task for the programmer. Tool: Makefiles using make
makefiles
output_target_name: dependencies.o instruction to compile
i.e
myprogram: main.o
<tab> linking command
myprogram: main.o list.o iter.o node.o
g++-5 -std=c++14 main.o list.o iter.o node.o -o myprogram
main.o: list.cc list.h node.h
g++-5
list.o: ...
Go into directory with the Makefile and run make to build. Run make clean to build the clean target instead the first listed target.
g++-5 is version 5, can say g++
Variables in Makefiles:
CXX = g++-5
CXXFLAGS = -std=c++14 -Wall
#CXXFLAGS = -std=c++14 -Wall -MMD
EXEC = myprogram
OBJECTS =
-MMD automatically infer dependencies using header files. Then, the Makefiles results in:
${EXEC}: ${OBJECTS}
${CXX} ${CXXFLAGS} ${OBJECTS} -o ${EXEC}
whether heap or stack allocated, compiler need to know that constructor exists.
virtual functions and defining books
attempt 1
struct Book
{
int typeFlag; //0
int numPages;
char* title;
char* author;
};
struct Comic
{
int typeFlag; //1
int numPages;
char* title;
char* author;
char* hero;
};
struct Text
{
int typeFlag;
int numPages;
char* title;
char* author;
char* subject;
};
int isItHeavy (void *bp){
int *ip = (int*)bp;
if (!*ip){
return *(ip+1) > 200;
} else if (*ip == 1){
return *(ip+1) > 50;
} else if (*ip == 2){
return *(ip+1) > 100;
}
}
class Book{
int numPages;
std::string title, author;
public:
Book(int numPages, std::string title, std::string author);
virtual book isItHeavy();
}
//Comic.h
class Comic : public Book {
std::string hero;
public:
Comic(int numPages, std::string title, std::string author, std::string hero);
bool isitHeavy() final override;
}
final keyword
- derived classes cannot override
- i.e. behavior isItHeavy() stays at that behavior
- prevents function from being overridden
- affects whether derived classes are creating a new function or not
- !!note that final can also be applied to a class, which means the class cannot be overridden/be used as a base class i.e.
class Rational final {};, which means the client can’t create derived classes of class Rational
override keyword
- specifier that tells the compiler that you’ll override the virtual function in one of the base classes
- Compiler will produce an error if it’s not actually overridden. Good spell check.
i.e.
Book* pb = new Comic(75, "C++ Man Saves the Day", "Bjarne Stroustrup", "Compiler");
pb.isitHeavy();
Compiler produces an error about overrides because the function name isn’t the same (either that, or the function signature), and hence isn’t overridden.
//Book.cc
Book::Book(int numPages, string title, string author): numPages{numPages}, title{title}, author{author}{}
bool Book::isItHeavy(){ return numPages>200 }
//Comic.cc
Comic::Comic(int numPages, string title, string author, string hero){
this->numPages = numPages;
}
Why won’t this compile?
-
numPages,titleandauthorare all private fields of Book, so we can’t even change them. -
No specification on how to construct Book. The steps of object creation will construct numPages, title, and author from the superclass Book, before constructing the fields of the base class. However, because this isn’t specified in the MIL, then Book will try to default construct, which doesn’t exist.
Note that this applies to all fields that need to be initialized: i.e. const fields, references
attempt 2 for comic
Make a getter to access private fields.
//Book.cc
int Book::getNumPages(){ return numPages; }
//Comic.cc
Comic::Comic(int numPages, string title, string author, string hero) : Book{numPages, title, author}, hero{hero} {}
bool Comic::isItHeavy(){ return getNumPages() > 50; }
Text class will look similar, with different fields.
Book *pb = new Book(150, "Jabronis", "Dwayne the Rock", "Johnson");
Book *pc = new Comic(150, "Jabronis", "Spider Man vs the Prague", "Stanley", "Spider-Man");
Book *pd = new Text(300 ...);
cout << pb->isItHeavy(); //False
cout << pc->isItHeavy(); //True
cout << pd->isItHeavy(); //False
int main(int argc, char* argv){
string whatToMake{argv[1]};
Book *pb;
if (whatToMake == "Book"){ pb = new Book{150...}};
else if (whatToMake == "Comic") ...;
else if (whatToMake == "Text") ...;
pb->isItHeavy(); //prints????
}
#include <iostream>
struct A {
int x = 5;
void foo() {cout << x << endl;}
};
struct B {
int x = 5;
virtual void foo() {cout << x << endl;}
};
-
sizeof(A) == 4which is the size of the integer -
sizeof(B) == 16which stores 8 byte ptr, and 4 byte integer. Hence, the compiler wanted the program to be word aligned: 8 byte ptr, 4 byte int, 4 byte padding. This pointer is called the virtual function’s table pointer.
why is it different??
For classes with virtual functions, the compiler will store an extra pointer in those objects (B). That pointer is what allows the compiler to do virtual dispatch. (Not reading into the future).
abstract classes and abstract base classes (abc)
The interface of BoolExpression: Can (and in some cases, must) have an implementation.
class BExp {
public:
virtual bool evaluate() = 0;
virtual ~BExp(){} // to NOT leak mem
}
=0 declares this function as pure virtual, essentially says that this function has no implementation. But pure virtual doesn’t mean that there is for sure no implementation (not an IFF relation)
A class with at least one pure virtual function is called an abstract class. You cannot instantiate objects of an abstract class.
BoolExpression b; is not ok, because no way of creating it.
If you can’t create objects, what are they good for???? Well, they are used as the base class in a hierarchy to define the interface.
= Abstract Base Classes (ABCs)
class BinaryOp : public BExp{
BExp *lhs, *rhs;
char op; //"l" or "&"
//can also use enums
public:
BinaryOP(BExp &lhs, BExp *rhs) : lhs{lhs}, rhs{rhs} {}
bool evaluate(){
if (op == '&') return (lhs->evaluate() && rhs->evaluate());
else if (op == 'l') return (lhs->evaluate() && rhs->evaluate());
}
~BinaryOP(){ delete lhs; delete rhs; }
}
class UnaryOP : public BExp {
BExp *child;
public:
UnaryOP (BExp *child) : child{child} {}
}
Atom = Atomic Node
class Atom : public Bexp {
bool val;
public:
Atom(bool)
}
class NegOP : public BExp {
BExp *child;
public:
NegOP (BExp *child) : child{child} {};
bool evaluate() {
return !child->evaluate();
}
~NegOp() { delete child; }
}
int main() {
BExp *b - new BinaryOP { new BinaryOp { new Atom {false}, new Atom{true}, 'l'}, new NegExp {new Atom {false}}, "&"}
}
When we call delete, the destructor of the function will indeed call binaryOp’s destructor through virtual dispatch. We need to make sure that the correct destructor is called. Hence destructors should ALWAYS be virtual
object destruction process
recall that creation is:
- allocate space
- make superclass
- create object fields
- run ctor body
hence destruction is in this order:
- destructor’s body runs
- fields that are objects get destroyed
- superclass component gets destroyed
- dealloc/delete space
attempt 3
Recall our book hierarchy :
Book, Comic : public Book, Text: Public Book.
Book &operator= (const Book &other){
numPages = other.numPages;
title = other.Title;
author = other.Author;
return *this;
}
Comic &operator= (const Comic &other){
Book::operator=(other);
hero = other.hero;
return *this;
}
Text &operator= (const Text &other){
Book::operator=(other);
topic = other.topic;
return *this;
}
Book *b = new Book {...};
Book *c = new Comic{...};
*c = *b;
class Book{
Book& operator=() ...
}
Note that they aren’t virtual. Will call book’s assignment operator, because the compiler sees 2 Book pointers, and has an operator between 2 dereferenced book references.
class Book {
virtual Book &operator=(const Book*);
}
class Comic {
Comic &operator=(const Comic*, &other);
}
Not a valid override, because parameter list is different. Book != Comic ultimately. Can say this though: Comic &operator=(const Book*, &other);, because Comics are Books.
Oh no.
r2hackma’s words: Shouldn’t implement them virtually.
*c = *b
return type of dereferenced Book pointer, gives you Book reference. Virtual function does virtual dispatch
LHS will virtual dispatch, at Comic’s assignment operator.
A text is a book, and now you’re being able to assign texts to book objects.
If the copy assignment operator is non-virtual, then assignment through base class pointers only does the base class assignment (called the partial assignment).
If it is a virtual function, then the parameters has to be a base class reference, and you get mixed assignments (i.e. a comic to a text).
If it isn’t a virtual function, then we have partial assignment.
Can’t be non-virtual, but can’t be virtual…. Does assignment through base class pointers make sense??
Assignment through base class pointers is generally a bad idea. We would like to disallow this.
disallowing pointer assignments
Attempt 1: make book assignment operator protected. Issue: users can’t assign books then.
Attempt 2: make all base classes abstract
Instead of:
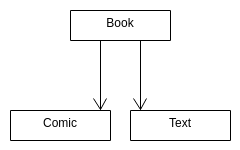
The structure of OOP should be:
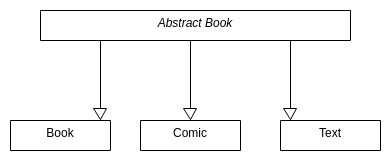
class AbstractBook {
int numPages;
std::string title, author;
protected:
AbstractBook &operator=(const AbstractBook &other){
numPages = other.numPages
...
}
public:
//rest of book class as before
virtual ~AbstractBook() = 0;
}
Note that the destructor should always be pure virtual, so that it can be abstract class.
Note2: leave isItHeavy() as pure virtual, so that we have at least one pure virtual, so that it can be an abstract class.
//AbstractBook.cc
AbstractBook::~AbstractBook(){}
What does this mean?
- You can’t use
AbstractBook b;. A class with at least one pure virtual method, is abstract. - You can’t use
AbstractBook *p1, *p2; *p1 = *p2, because it’s protected.
This implementation solves our problems. You can’t base class assign something that you can’t create.
defining a chess board
class CheckBoard {
char **board;
public:
ChessBoard();
void PrintBoard();
void PlayTurn(string s);
...
}
void ChessBoard::PrintBoard(){
for (int y = 0, y < height; ++y){
for (int x = 0, x < width; ++x){
cout << board[y][x];
}
cout << endl;
}
}
What if I want to display my code in another stream??? Have to re-implement everything :((
attempt 1: could make the function take in a stream as parameter input. Okay, but what if I want tot display it graphically???
attempt 2: what if I want both textual and graphical???
should my class ChessBoard be talking to the user at all???
Our chessboard shouldn’t be talking to the user at all, it should have only one reason to change: game logic state and display.
single responsibility principle
A class should have only one reason to change.
We should have a separate display for our model (data).
observer pattern
Subjects: (pub)
- represent our data or the thing the observers are interested in.
- keep track of its observers, and notifies them when a state changes.
Observers: (sub)
- interested in the subjects
- react appropriately to modification or change in them.
class Subject{
vector<Observer*> obs;
public:
void attach(Observer* o) { obs.emplace_back(o); }
void detach(Observer* o) {
for (auto it = obs.begin()l it != obs.end(); ++it){
if (*it == 0){
obs.erase(it);
return;
}
}
}
void notifyObservers(){
for (auto ob : obs){
ob -> notify;
}
}
}
Note: using an iterator on a mutated vector is undefined behavior!!!!! ^^
for-range: syntactic sugar is syntax within a programming language that is designed to make things easier to read or to express. It makes the language “sweeter” for human use.
class Observer{
public:
virtual void notify() = 0;
virtual ~Observer(){}
}
pure virtual method notify
class HorseRace : public Subject {
ifstream raceFire;
string lastWinner;
public:
HorceRace(string fname) : raceFile {fname}{}
void doRace(){
raceFile >> lastWinner;
notifyObservers();
}
}
class Bettor : public Observer {
string name, horse;
HorceRace *hr;
public:
void notify() override {
cout << name << (horse == hr->getState()? "wins!" : "loses") << endl;
}
}
Bettor(string name, string horse, HorseRace *hr): name{name}, horse{horse}, hr{hr} {
hr->attach(this);
}
~Bettor(){
hr->detach(this);
}
Still have the issue of observers outliving the subject. Can’t live past the data that you’re observing.
If subject goes out of scope before the observer:
HorseRace* hr = new HorseRace{ ... };
Bettor b{..., hr};
Bettor c{..., hr};
delete hr;
Now Bettor b and c are holding the dangling pointer hr, which is already deleted. You don’t want the client to manage the memory.
uml diagrams
UML stands for Unified Modeling Language. We’re going to talk about Class Diagrams, with the purpose of communicating OOP design.
Implementation agnostic.
syntax


- - is private
- + is public
- * is protected
- virtual is italicized
- abstract base classes should have name italicized
uml example 1
Foo
- myName : string + myAge : int
+ doThing(p : int) : void
relationships in uml
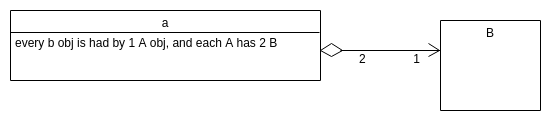
aggregation
- Aggregation: class A contains references (but not c++ references) to class B, but does not own it.
Example:
class A{
vector<B*> bs;
public:
~A();
}
Draw diamond to the owner/”contains” class. Draw arrow to the class that it “refers” to.

If A has a B, in general, B’s lifetime is not tied to A. That is:
- B has an existence outside of A.
- If A is copied, B is not (shallow bytewise copy)
- If A dies, B lives on
We can specify multiplicities (how many) relationships.
 Means that each A object has n B objects.
Means that each A object has n B objects.
 Means that each A object has 1 to n B objects.
Means that each A object has 1 to n B objects.
 Means that each A object has 0 to infinity/many B objects.
Means that each A object has 0 to infinity/many B objects.
 Means that each A object has 4 to infinity/many B objects.
Means that each A object has 4 to infinity/many B objects.
Note: multiplicities on the other side is also valid
 Means that each B is held by exactly 1 to 3 A.
Means that each B is held by exactly 1 to 3 A.
Here is both:
 Means that each B is held by exactly one to 3 A, but each A has 2 to many B.
Means that each B is held by exactly one to 3 A, but each A has 2 to many B.
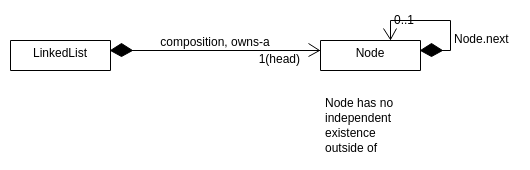
composition
- Composition: “owns-a” relationship.
- If A owns a B, then B has no independent existence outside of A.
- If A dies, so too does B
- If A is copied, B is copied too (deep copy)
- LinkedList owned its node,node’s also owned their next Node
- Typically implemented as an object field, or an owning pointer.
If you copy a subject, it does not own the pointer. LinkedLists want to own pointers of their node, which is a composition relation
specialization
- Specialization: inheritance, A “specializes” B or A “is_a” B relationship.
- If A is-a B (which is almost always how inheritance in c++ should be implemented), then everything that you can do in B, you can do in A (because a B is an A).
- Implemented in c++ via public inheritance

more examples
class A {
B b1;
B b2;
}
A concrete example:
class Resident {
Address mailing_address;
Address billing_address;
}
observer pattern in uml
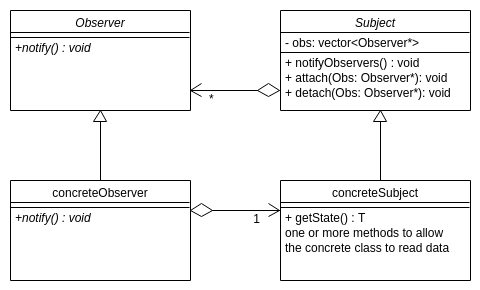
inheritance levels in c++
case 1: public B
class A : public B
All public functions of B are accessible through A as well. the keyword public is a cap, or limit on the visibility of inherited fields or methods.
Which means, you have the same visibility as the class that you inherited from.
class B {
int x;
protected:
int y;
public:
int z;
}
Then in A:
- x is still private, A can’t access
- y is still protected, A and derived classes of A can access
- z is still public
case 2: protected B
class A : protected B
A is not a B. Everything public in B is protected in A. This is not a is-a relationship. B should then be a field in A.
In A:
- x is still private, A can’t access
- y is still protected, A and derived classes of A can access
- z is now protected in A
case 3: private B
class A : private B
Everything public and protected in B is private in A. This is not a is-a relationship.
In A:
- x is still private, A can’t access
- y is now private, A and derived classes of A can’t access
- z is now private
vectors in c++
#include <vector>
- vector is a templated class that encapsulates a dynamically growing array.
- guaranteed by the std to place data contiguously in memory
Uses:
vector<T> vec;is an empty vector of T objectsvector<int> ints;is an empty vector of intsvector<int> ints{3,4};is an vector of {3,4}
Note that curly braces constructor can also be overloaded: as a member list initialization syntax.
Can be overloaded for vectors, gives you the vector with that list as its contents. i.e. vector<string> vec{"..", "..", ....};
template <typename T>
class vector {
public:
vector(size_t n, T val);
}
This constructor creates a vector of n vals. vector<int> ints(3,4); is an vector of {4,4,4,4}. Only confusing when your type T is also size_t.
accessing a vector
- can be indexed like an array.
- unchecked like an array: i.e. V[i], V[10000] … leads to undefined behaviour
Uses:
vector<T>::size()gives the number of elements in a vector v.size();
error handling
vector::at(size_t i) is a checked version of the index operator: checks if the index is out of bounds, and if it is, gets mad.
Error handling is inherently a non-local problem.
- callee (
vector::at(size_t i)) can detect the error, but doesn’t know what the caller (user) want to do about that. - caller knows how to handle an error, but can’t detect errors
attempt 1: error handling with sentinel values
In c:
- uses sentinel return value (aka flag value, trip value, rogue value, signal value, or dummy data)
- if a function is always meant to return a positive value, allow its return type to be signed and return -1 on error, or use distinct negative values as error codes
The sentinel value is a form of in-band data that makes it possible to detect the end of the data when no out-of-band data (such as an explicit size indication) is provided.
Sentinel value not ideal:
- reduces the range of values that your function can return
- not always possible:
- in
vector<t>, as the client/person writing vectors, don’t even know what type is stored in it - can’t choose sentinel values - even if it was int, the entire range of negative values are valid returns
- in
- requires cumbersome checks on client code, which can’t be enforced
- program continues on as if nothing happened if client doesn’t do anything, quite bad.
attempt 2: c++ exceptions for error handling
The function that detects an error will raise or throw an exception (if it can’t recover itself). don’t use it as your flow control.
Either some caller down the call chain catches that exception, or the program terminates.
Exception in c++ is anything that is thrown: anything in c++ can be thrown. But typically, we would like to use meaningful error classes as exceptions.
To raise an exception, we use the keyword throw.
Note that throws clause is deprecated.
#include <except>
int at(size_t i){
if (i > mySize){
stringstream ss;
ss << "Index: " << i << " out of bounds:" << mySize;
throw std::out_of_range{ss.str()};
}
}
The std exceptions all take a string param in their constructor, that is meant to describe what went wrong for error reporting purposes.
example: what does this program print?
int Foo(){
throw 10;
cout << "Hi" << endl;
}
int Bar(){
Foo();
cout << "Bar" << endl;
}
int main(){
Bar();
}
when an exception is thrown, the current executing function stops, and stack unwinding occurs.
stack unwinding
Occurs when a function ends, and the function stack frame is popped off.
All stack allocated data is freed, and then the exception/stack unwinding propagates down the call chain, until a matching try/catch is found.
If main propagates an exception, then the program terminates.
Previous example’s unwinding:
- Foo throws 10
- Foo propagates exception (Hi doesn’t get run)
- Bar get exception
- Bar doesn’t catch, propagates exception (doesn’t print Bar)
- main gets exception, propagates exception
- oops program terminates.
With catch modifications:
int Foo(){
throw 10;
cout << "Hi" << endl;
}
int Bar(){
try{
Foo();
}
catch (int) {
cout << "caught an int" << endl;
}
cout << "Bar" << endl;
}
int main(){
Bar();
}
Exception unwinding:
- Foo throws 10
- Foo propagates exception (Hi doesn’t get run)
- Bar get exception
- Bar catches int-type exceptions (foo wrapped in try catch), handles by printing “caught an int” and continues Bar execution (prints Bar)
- main does not see exception
- main continues program execution
For more information on the error:
int Bar(){
try { Foo(); }
catch (int n) { cout << "caught int " << n << endl;}
cout << "Bar" << endl;
}
try { v.at(100000000); }
catch (std::out_of_range e){
cout << e.what();
}
catch (int) { ... }
catch (Foo) { ... }
.what() is a function all the std errors provide that returns the string they were constructed with.
error is passed from function frame to frame similar to a return value.
throw by value, catch by reference
int Foo(){
throw C{1,2,3};
}
int Bar(){
try{
Foo();
}
catch (A a) {
cout << "caught A" << endl;
}
catch (B b) {
cout << "caught B" << endl;
}
catch (C c) {
cout << "caught C" << endl;
}
}
int main(){
Bar();
}
First matching handler is executed, in this case the one for A, because C “is-a” A.

similarly, but virtual dispatch
struct X {
virtual void hi(){
cout << "x" << endl;
}
};
struct Y : public X {
virtual void hi(){
cout << "y" << endl;
}
};
struct Z : public Y {
virtual void hi(){
cout << "z" << endl;
}
};
virtual foo() {
throw z;
}
int main() {
try{
foo();
}
catch (X x){ x.hi(); }
catch (Y y){ y.hi(); }
catch (Z z){ z.hi(); }
}
matches the first matching handler, a z is-a x, so the X one matches. X is a local copy of the object thrown, so virtual dispatch doesn’t happen. X::hi() is called, which prints X.
So, general maxim in c++ is throw by value, catch by reference.
int main(){
try { foo(); }
catch (X &obj) { obj.hi(); }
catch (Y &obj) { obj.hi(); }
catch (Z &obj) { obj.hi(); }
}
The first catch block is still the one that executes, but now virtual dispatch must occur, since the compiler can’t know the runtime type of obj, so it prints out z properly.
When a matching handler is not found, the same exception is being propagated through the call chain until a matching handler is found.
A function can catch an exception, and:
- completely resolve it
- do some cleanup and throw a new exception
- do some cleanup and rethrow the same exception
int bar(){
throw z;
}
int foo(){
try { bar() }
catch(x &obj) { throw obj; }
}
int main() {
try { foo(); }
catch(z &obj) { throw obj; }
}
foo calls bar, which throws a Z type, that foo catches. But foo’s exception handler rethrows an X, which is not a Z. The main’s exception handler doesn’t type match and the program crashes.
throw obj; doesn’t behave as we like because it changes the type being thrown to the type caught.
Could write more handlers, and order from most derived to least derived…
what if i dont want to write catches for every type
To rethrow the exact same thing, use throw;. Can’t be used outside of a handler.
dealing with memory leak caused by exceptions
main received and deleted array1
ret* gets created with new, but is never returned to main…. so no one is able to delete this ptr.
If a function has resources (memory, network sockets, file pointers….) and an exception is throwing during its execution, how can you guaranteed that that those resources are freed?
To solve this: catch exception, do cleanup, rethrow
try{
foo(i);
} catch (BadBehaviour &obj{
delete p;
}
But you don’t want to write duplicate try-catches. Code duplication is :
- error prone (i.e. if change in one location, need to manually propagate)
- tedious
How can we guarantee that cleanup code is always executed at the end of our function regardless of how it terminates (exception, return)?
attempt 1: catch-all with ... syntax
void foo() {
//allocation
try{ code }
catch(...) { free rsc, rethrow? }
}
Downsides:
- sometimes, allocation happens only if some condition is met,
- not in the spirit of exceptions
- doesn’t clean up when the code returns properly on exit
attempt 2: RAII
Note that the destructor will always run!!
Use objects to wrap around, such that no matter how the function exits, stack unwinding happens and resources are destructed.
Note that stack allocated data is always freed. As well, the destructor of any stack allocated object will run. Hence, make sure that all that needs to be cleaned up is in stack allocated destructors.
For example, consider:
int* getArray(int begin, int end){
int* array = new int[end - begin];
int i = begin;
while (i != end){
array[i - begin] = i;
//throw exception here, if mem leak array ptr is lost
++i;
}
return err;
}
The array might memory leak, which results in dangling ptrs. So, wrap arrays in a stack allocated object that manages them, such that the destructor frees them, and this is no longer a problem.
Actually, wrap all resources in a stack allocated object that manages them. == resource acquisition is initialization
resource acquisition is initialization (RAII)
Any time you acquire a resource (ex: memory, file pointer, network socket… ) it is only by initializing some stack allocated object which manages it.
To encapsulate the previous dynamically allocated array example:
vector<int> getArray(int begin, int end){
vector<int> array;
while (begin != end){
array.emplace_back(begin);
++begin;
}
return array;
}
which happens to be an existing wrapper to array: std::vector.
exception safety
In case new fails, it throws an exception.
Going back the the assignment operator of the node class
Node& Node::operator=(const Node& other){
if (this == &other) return *this;
delete next;
next = new Node{*other.next};
data = other.data;
return *this;
}
the invariant of Node:
The next ptr is one of 2 things:
- nullptr
- a valid ptr to a heap allocated node
But here, if new fails, then our old next is still deleted and we are left with a dangling ptr.
Even if the client caught the dangling ptr exception, the LinkedList is irreparable.
throwing exceptions and destructors
never ever ever ever allow your destructors to throw or propagate an exception
why?? what happens when an exception is thrown? stack unwinding, to look for a matching handler, while stack unwinding is happening.
The entire reason you follow RAII is for stack allocated resource cleanup when exceptions happens and the stack unwinds, by invoking the destructor.
There’s really no good way to handle 2 uncaught exceptions. So, if you’re cleaning up other exceptions, and a destructor can throw, AND throws an exception, your program immediately terminates due to these 2 uncaught exceptions.
that means:
- rest of cleanup isn’t done at all
- no chance to recover where you might have been able to, with the first (perhaps mild) exception
example:
class Bad {
public:
~Bad { throw 5; }
}
int foo() {
throw 10;
}
int bar(){
Bad b{};
foo();
}
int main()
try{
bar();
} catch (int n){
cout << "caught" << n << endl;
}
- foo throws 10
- bar doesn’t handle foo’s thrown exception because it doesn’t have a matching try-catch
- bar undergoes stack unwinding
- object b is destroyed during stack unwinding
- destructor of b throws another exception
= there are 2 active exceptions, program terminates, main never handles the exception.
hence, always declare your destructors noexcept
exception safety tiers
Levels of exception guarantee
- nothing
- basic guarantee
- strong guarantee
- no-throw guarantee
nothing
Program may be in an invalid state i.e. Node::operator=.
basic guarantee
If a function offers the basic guarantee, it promises that if it throws or propagates an exception, then the program will be left in a valid but unspecified state
Definition: valid means that no resource leaks, no invariants are violated.
strong guarantee
If a function throws or propagates an exception following the strong guarantee, the program state will be left as if nothing occurred, as if this function was never called.
i.e. vector.emplace_back(), program state leaves as if emplace_back() was never called.
- if array is full, allocate bigger array (double it)
- copy all elements over
- emplace back
- free the old array
We don’t care about the old array values, so it makes more sense to move the elements of the old array into the new realloc-ed array. But what happens if the move constructor throws in the middle??
A moved-from object is no longer valid, and will leave the old array in a invalid state. emplace_back offers the strong guarantee, but using move will violate the strong guarantee. Hence, emplace_back will use the copy constructor to keep the old array intact while creating the new array, unless the move constructor is declared as noexcept. !!!
no-throw guarantee
This function will always complete its task and never throw an exception. (Relates beyond the design of the function itself)
Tell the compiler of the no-throw guarantee with the keyword noexcept.
class Node{
Node& operator=(Node &&other) noexcept{
swap(next, other.next); //assign ptrs (numbers)
swap(data, other.data); //assign plain ol data ints
return *this;
}
}
Note:
- pts are both existing –> noexcept
- pod assignment usually ok unless your hardware is broken –> noexcept
Hence operator= is noexcept
Should declare any possible function which doesn’t throw as noexcept, facilitates compiler optimization.
example
What guarantee does bar() offer???
class A {
public:
void foo(); //strong guarantee
void baz(); //strong guarantee
void bar(){
foo();
baz();
}
}
aka, is exception guarantee transitive??? nope
Note that neither foo() nor baz() are const function:
- if foo() throws, then bar hasn’t changed
- if foo() succeeds and mutates object A, but baz() throws, then
Ahas changed in bar() has changed and is not a strong guarantee
Hence at best, it offers the basic guarantee.
How can bar() offer the strong guarantee? i.e. kind of like undo the mess of foo().
But undo-ing is impossible, violates the nature of wrapping things up in function because otherwise bar() would need to know exactly what foo() does such that it can undo foo().
We can rewrite the function as such:
class A {
public:
void foo();//strong guarantee
void baz(); //strong guarantee
void bar(){
B temp{b};
temp.foo();
temp.baz();
swap(temp, b);
}
}
But what if swap throws? Still the same problem
non-throwing swap
a non-throwing swap for user-defined classes is at the heart of writing exception safe code in c++
How to write a non-throwing swap??? We can swap() nothrow but we still need to copy especially if it’s not a POD (i.e. use object’s copy ctor) … and copy might throw.
What’s a copy that will never throw? Any plain-ol-data or pointer!
This leads to the pImple idiom.
pointer to implementation (pImpl) idiom
Idea:
- take all the fields out of your class and create an implementation struct that stores them
- now your class just holds a ptr to an object of that struct type
class XWindow{
Display *d;
Window *w;
int gc, gx;
}
Do we know what all these fields mean? Do we care??? No, we don’t care about the implementation of the fields: it’s an abstraction resulting in an interface.
If the creators of Xwindow class decide to change the layout of the class or the underlying implementation, lead to compilation dependencies: changes imply that all client code that uses XWindow object is recompiled.
The pImpl idiom solves this:
struct XWindowImpl{
Display *d;
Window *w;
int gc, gx;
}
implemented in the header.
And class XWindow just needs to store the XWindow implementation XWindowImpl.
class XWindow{
XWindowImpl *pImpl;
}
There is no recompilation need of all code that uses XWindow, we just need to recompile XWindow.cc itself, and relink to the client code using XWindow.
Small change to client code: All field accesses to XWindow need now to be prefixed pImpl->: example w to pImpl->w
benefits of pimpl
- we can completely change the implementation of the class without client code needing to recompile
- we can trivially provide non-throwing swap with:
void swap(XWindow &lhs, XWindow &rhs){ swap(lhs.pImpl, rhs.pImpl); }
= The added level of abstraction maintains the separation between the implementation and the client usage
reasons to not pimpl
- RAII says the squiring of a resource should onnly be done through initialization of a statically allocated object who manages it
aka you don’t pay for what you don’t use
instances of pImpl usage
- vectors for heap allocated arras
- fstreams for file pointers
But what about individual heap allocated data (not an array)?
Foo *genFoo(){
Foo *ret = new Foo();
if (...) return;
else {}
}
This does not follow RAII, because if anything throws, we have a memory leak!!
If you follow RAII strictly, you will never see the keyword new.
smart ptrs
If we don’t use new, we could write a class that manages Foo* for us. But c++ has classes for wrapping parents already! std::unique_ptr<T>, std::shared_ptr<T> are included in #include <memory>.
#include <memory>
using namespace std;
unique_ptr<Foo> genFoo() {
ret{ new Foo() };
} //unique_ptr<Foo>
Better:
auto ret = make_unique<Foo>( /*ctor args*/ );
If any of this throws, unique_ptr
unique_ptr assumes sole ownership of the memory that it points to. As such,
what not to do:
int *p = new int;
unique_ptr u_p{p};
{
unique_ptr p2{p};
}
Note that p2 does out of scope, deletes p;
u_p is now a dangling ptr aaaaaa.
BUT shared_ptr! can be copied, because it is shared, and will only delete its data when the last shared_ptr to that data dies.
shared_ptr maintains a ref count of the shared_ptrs to that data.
Is when a shared_ptr is created, it allocates a size_t ptr and sets that number to 1. It is the only shared_ptr to that data.
When you copy construct a shared_ptr, when that size_t ptr is shallow copied so that share the same count. The size_t is incremented
~shared_ptr decrements the ref count, checks if its 0 after decrementing, if it is calls delete on the ref count and the data ?????????
{
shared_ptr<int> sp = make_shared<int>{s};
{
shared_ptr<int> sp2{sp};
//ref count is 1
}
//ded but still 1
}
//ded for reals
smart ptrs tl;dr
- Smart pointers can be used in all the same ways raw pointers can be
- If necessary, you can still access the raw pointer with the
getmethod - You should make sure you always non-own the smart pointer
- The smart pointer need to outlive the non-owning pointer, otherwise you’ll still get dangling pointers
- With smart pointers, you’ll never need to use the
new/new[]anddelete/delete[]
the decorator pattern
We want to have an object hierarchy where at runtime we can mutate the behavior of the relevant functions provided by that hierarchy
i.e. adding or removing functionality at runtime
the pizza problem
We want to create a pizza ordering system where the user can add things to the pizza, changing the price and description.
class Pizza {
public:
virtual float price() = 0;
virtual string desc() = 0;
virtual ~pizza(){};
}
class CrustAndSauce : public Pizza(){
public:
float price() override { return 5.40; }
string desc() override { return "Pizza" }
}
Composition or aggregation?? Potential client code:
Pizza *p = new CrustAndSauce{};
p = new Topping{"Ham", p};
p = new Topping{"Pizza", p};
p = new FreeExtra{"Well Done", p};
How to delete??
//option 1
//
option 2 is valid if you really don;t want your object owning your decorator
We’ll go with option 1 (owns-a decorator, filled in diamond)
This is a design decision.
This is Abstract
class Decorator : public Pizza{
protected:
Pizza *base; //so that toppings can access it
public:
~Decorator() { delete base; }
Decorator(Pizza *p);
}
class Topping : public Decorator{
string topping;
public:
Topping(string t, Pizza *p): Decorator{p}, topping{t}{};
float price() override {
return 1.49 + Decorator::price();
}
string desc() override {
return base->desc() + "with " + topping;
}
}
If we dont want Pizza *base protected, then we would just override it in decorator (which makes it non abstract anymore)
Instead of calling base::price we call
If you inherit pure virtual functions but don’t declare them as abstract.
class FreeExtra: public Decorator{
string extra;
public:
string desc(){
return extra + base->desc();
}
}
Now the client code is:
int main(){
Pizza *p = new FreeExtra{"A well done",
new Topping{"basil",
new Topping{"pineapple",
new Topping{"ham",
new StuffedCrust{new CrustAndSauce}}}}};
cout << p->desc() << endl;
}
This is like a stack, but a stack has to manually do the concatenation.
The output would be: A well done pizza with stuffed crust with ham with pineapple with basil. The outermost is printed last because of the recursive call.
Since this is an owning (has-a) relationship, all memory is deleted.
Good thing about the decorator pattern is that you can: myPizza[0] = new Topping{"cheese"}; to add new toppings even after the creation of the pizza.
The creation is essentially a linked list of objects: stuffed crust -> pepperono -> crust and sauce
The removal of the pepperono results in: stuffed crust -> crust and sauce.
the strategy pattern
Suppose you have some task you want to achieve but the different classes achieve it differently i.e. different level of difficulty cpu players for chess require different implementations.
Basically the idea is literally virtual methods (i.e. makeMove) and have all the derived classes override it which their specific behaviour. polymorphism.
What if we want to make sure that at the beginning of each makeMove, the cpu’s regardless of difficulty should check if there is a checkmake in one (if there is a move to immediately win), then the cpu should take it.
Want to enforce some general behaviour that they all should follow. This implementation does not allow that.
class cpuPlayer{
public:
virtual void makeMove() = 0;
virtual ~cpuPlayer();
}
We could copy and past the check for checkmate into every override method. BUT is error prone, tedious, bad.
non virtual interface idiom (nvi)
A virtual method is a “hook” for our derived classes to inject specialized behaviour.
A public method is part of the interface to the client.
A public virtual is both (a hook for the derived as part of the client interface).
The NVI idiom states that:
- all public methods should be non-virtual
- virtual behaviour that you want to provide for the clident should be a non-virtual public method
This is an idiom that in most cases, you have no reason to not follow:
- it is a lot easier to enforce control on your public interfaces from the get go, rather than to regain control later (i.e. if you wanted to split doMove() into a few smaller functions, you can do so in the implementation, and just stick all 3 methods in a sequence in the public non-virtual makeMove() function
In order for our base class ???
The base class cannot have virtual public methods ???
The abstract base class has no control over what ????? ??
Rewrite as such:
class cpuPlayer{
virtual void doMove() = 0;
public:
void makeMove() { doMove(); }
virtual ~cpuPlayer();
}
Where the concrete base class is:
class easyCPU : public cpuPlayer{
void doMove(){
... //code for easy strategy
}
public:
void makeMove() { doMove(); }
virtual ~cpuPlayer();
}
Yes! private methods can be virtual and derived classes can override them
class mediumCPU : public cpuPlayer{
void doMove(){
... //code for medium strategy
}
public:
void makeMove() { doMove(); }
virtual ~cpuPlayer();
}
If we want to enforce some behaviour that always occurs regardless of which derived type the object is, we can place it in the non-virtual makeMove function.
i.e.:
class cpuPlayer{
virtual void doMove() = 0;
public:
void makeMove() {
checkMateInOne();
doMove();
}
virtual ~cpuPlayer();
}
What if we were creating a video game. In this game we have easy and harder levels () and we have 2 types of enemies: turtles and bullets.
the policy/strategy we want to follow to create levels is different per level:
- in the easy levels we want more turtles than bullets with some probability
- in the harder levels the opposite is true
Create a virtual method createEnemy();
Factory method pattern is just strategy pattern to a policy of object creation.
templates (post midterm)
vector<Foo> v;
We’ve already seen classes in the stl, like vector and smart pointers, where the type itself is parameterized when declaring an object.
When declaring an object of that type, you must provide another type inside the < >.
What’s actually going on here??
back to the iterator pattern
An iterator is any type for which !=, unary* and operator ++ are provided.
A class that implements the iterator pattern provides begin and end that return iteratos.
void for_each(iter start, iter end, fn f){
while (start != end){
*start = f(*start);
++start;
}
}
Well how can we do this?? Currently what if we wanted to run this function on our iterators for our LinkedList example from class and our ConnectX iterator from assignments.
We’d have to write 2 functions…
void for_each(LinkedList::iterator start, LinkedList::iterator end, int (*fn) (int));
void for_each(ConnectX::iterator start, ConnectX::iterator end, int (*fn) (int));
… we’d have to write different functions for each type of container, even though the inside implementation is basically the same.
We could try creating an Abstract Iterator type, which defines the interface of iterator types (albeit not well, because now every thing that is an iterator must inherit from it).
Also, that still doesn’t solve the problem of these functions having different types.
Sometimes an interface is insufficient. An ABC is really just defining an interface, and that isn’t sufficient enough: a raw pointer is an iterator by definition (has !=, *, ++).
But a pointer is a POD, it can’t inherit from an interface. What do we really want to say for our types that our functions consume????
Writing a function over our AbstractIterator is insufficient to operate over all iterators.
What we really mean about the types this function takes is: any type for which !=, *, ++ are defined.
the answer to type-specific iterators is templates
To write a template function, you start with the template keyword.
template <typename T>
T max(const T& lhs, const T& rhs){
return lhs > rhs? lhs : rhs;
}
template <typename T> says we have ONE template we’ll refer to as T in our function, T will essentially get replaced with whatever type the client parameterizes with.
For which types can max me used on?
Any type that has:
operator>defined for that type (comparable), that returns a type that is implicitly castable to a bool- copy ctorable (because we return by value)
- (specific type listing isn’t an acceptable answer on a final)
The requirements of a template type are only exactly what’s enforced on it, by how that template type is used. Templates use duck typing i.e. if it walks like a duck and talks like a duck then it is a duck ah yes
A note on using template functions: if then compiler can unambiguously deduce the type then you don’t need to parameterize that function.
example:
int x = 10;
int y = 0;
max(x,y); //valid
example:
template <typename Iter, typename Fn>
void for_each (Iter& start, Iter& end, Fn f){
while (start != end){
*start = f(*start);
++start;
}
}
types allowed:
for Iter
- have
!=defined between Iter, - unary
*on iter must return a type that either is the same, or is implicitly castable to the type of parameter of Fn - dereferenced must return an l-value
- prefix operatir ++ is defined
for Fn
- must be callale as a single pamater fn (type must match between param and *Iter)
- return type for Fn must match *Iter
exists in the STL???
Note that we had templated them like this: max<int>(5,4); parameterizing the function with type int.
However, template functions do not have to be manually or explicitly parameterized.
implicit parameterization
The type of the template argument can be unambiguously deducible, hence you wouldn’t need to explicitly parameterize it.
i.e. max(5,4); automatically parameterized
So, template functions are incredibly useful when the abstraction that you want to work over is not a specific type, but rather a set of behaviour.
templating classes
Classes can be templated too. Consider a LinkedLst, if stores only integers as its data. If we wanted it to store something else, we’d have to copy and paste all of LinkedList and only change the type of data everywhere.
template <typename T>
class LinkedList {
struct Node {
T data;
Node* node;
}
Node* head;
public:
void addToFront(T data){
head = new Node(data, head);
}
class iterator {
Node* curr;
iterator (Node* c) : curr{c} {}
friend class LinkedList<T>;
/* ... */
//LinkedList is an incomplete type, must specify which type to template it with.
//The only change is the return type of the dereference unary * operation
T& operator*() {return curr->data; }
}
}
Now we can create LinkedLists over any type of data that matches the way we use it, as long as T is copy constructable.
Client code usage:
LinkedList<string> ls;
ls.addToFront("hi").addToFront("aloha");
// aloha -> hi
- If you don’t template it: incomplete type error
- If you use an incompatible type: compiler will say here’s a list of possible types that can work…
If we’ve defined the Big5, then we have a copy ctor, which means that we can have linkedlists of linkedlists!
LinkedList<float> lf;
LinkedList<LinkedList<LinkedList<int>>> lololi;
Sidenote: LinkedList of LinkedList of LinkedList… tokenizing >>> is very hard. Ambiguous grammar, still broken. i.e. templating with int.
Now LinkedList is a considerably more powerful and useful class, and we didn’t have to write any new code.
behind the scenes behaviour
How does this actually work??
The first time that the compiler sees you parameterize a template function or class with a type that you haven’t used yet, it creates a whole new function or class of that type.
Consider this example:
LinkedList<string> ls;
LinkedList<float> lf;
LinkedList<LinkedList<LinkedList<int>>> lololi;
Compiler will create 5 LinkedList class during compile time:
LinkedList<string>LinkedList<float>LinkedList<int>LinkedList<LinkedList<int>>LinkedList<LinkedList<LinkedList<int>>>
This is why the implementation has to be provided in the header file. (can be written further down, but still in the header file).
If the implementation of LinkedList is in the .cc file, the compiler can’t check if the types are valid, nor can’t generate the different functions/classes for the different types.
Hence, become of this, template method/functions must be defined (not just declared) in the header file, otherwise the compiler couldn’t create that new type of class/function when it sees a new type.
side note: can compile main with '-c'
simplified shared_ptr with templates
We’re not going to write make_shared(), but still going to consider the big 5.
template <typename T>
class shared_ptr{
T* data;
size_t count;
}
destructor
Let’s first consider our destructor.
We want sharing between different objects. Don’t use static because that’s sharing between the entire class. Use pointers.
shared_ptr::~shared_ptr(){
--(*count);
if (*count == 0){ // !(*count)
delete data;
delete count;
}
}
constructor
shared_ptr::shared_ptr(T* p): data{p},count{new size_t{1}} { }
Note that making two shared pointer from the same raw pointer, both will think that they are the first and only one, and thus, when you kill one shared pointer, you lose your raw pointer because it will delete itself.
copy constructor
We are becoming a copy of another share pointer.
shared_ptr::shared_ptr(const T* other): data{other.data}, count{ &(++(*other.count)) } { }
which is basically:
shared_ptr::shared_ptr(const T* other): data{other.data}, count{ other.count } {
++(*count);
}
If the user doesn’t make another shared pointer to the same piece of data without using a shared_ptr copy constructor, then there is nothing we can do about it. (I guess we could implement a giant map of the pointer addresses)
move constructor
Can’t set count to a nullptr because when it goes out of scope. Hence, you could just increment count as a solution. Which is the same as the copy constructor
So hence, don’t write it at all.
//tada just use the copy constructor
copy assignment operator
shared_ptr& shared_ptr::operator=(const shared_ptr<T>& other){
--(*count);
if (*count == 0){ // !(*count)
delete data;
delete count;
}
data = other.data;
count = other.count;
++(*count);
}
move assignment operator
Same as copy assignment operator intuitively.
== big 3 instead of big 5
variadic templates
templated max function is nice, but what if we want the max of an arbitrary list of items? instead of between 2 elements only.
Make variadic templates using a “parameter pack”.
template <template T, typename... Rest>
T my_max(T first, Rest... rest){
T maxRest = my_max(rest...);
return first > maxRest ? first : maxRest; //needs base case still
}
We need a base case, actually as a separate function
template <template T>
T my_max(T t){
return t;
}
Note that this variadic max function casts types:
i.e.
my_max(12.5, 13.0, -1, 213.5); //returns 213
Equivalent to:
float my_max(12.5, 13.0, -1, 213.5);
float my_max(13.0, -1, 213.5);
int my_max(-1, 213.5);
int my_max(213);
Whereas:
my_max(12.5, 13.0, -1.0, 213.5); //returns 213.5
template meta programming
Every time the compiler sees an instantiation of a template it hasn’t seen before, it creates a new class or function with that instantiation.
Template, other than types, can also take integer values.
you can combine these two pieces of information to compile things at compile time.
This is called template, meta programming.
very little reason to use this in c++, maybe in hardware drivers……..
template <long long N>
struct Fib< ???? >
How can we store a number in a clasS?? static fields
template <long long N>
struct Fib{
const static long long val = Fib<N-1>::val + Fib<N-2>::val;
}
That’s our recursive call. How do we make the base case?? Template specialization!
template<>
struct Fib<1> {
const static long long val = 1;
}
And for the n-2 recursive call:
template<>
struct Fib<0> {
const static long long val = 1;
}
This is different from getting the val from a function. What is the Fib calculation O() ??
This is actually memoized by the compiler.
When printed out, it’s constant time! But the integers for Fib<?> have to be there on compile time, must be integer constants.
Compile time is going to be linear tho
MISSING SOME SLIDES HERE
how to tell the client what the implementation do, and how to use it
signature about syntactic requirements
specification about the modules behaviour
interface specification
contract between the module’s provider and the client programmer, that document each other’s expectations.
- tells
- document correct usage of an existing module
benefits of modularity
hook
Precondition: constraints that hold before the method is called
//requires
Postcondition: constraints that hold after the method is called, assuming that the precondition holds.
//modifies
//throws
//ensures
//returns
ex1
sumVector, use prefix increment.
//requires that vect is validly constructed (redundant, should be implicitly true)
//requires the content of vect are such that addition in order will not overflow
(are sufficiently small that their value should not cause sumVector to overflow)
//returns sum of vector
ex2 : replace
int replace(std::vector<int>& vect, int oldElem, int newElem){
for (int i = 0, i < vect.size(), ++i){
if (vect[i] == oldElem){
vect[i] == newElem;
return i;
}
}
}
replace an element in vector, return position of new element
//requires: oldElem to actually be in vector
//modifies: vect
//ensures: let i be the index of oldElem in vect such that there doens't exist q in Natural numbers or q less than i, and vector[q] = oldElm. Then, vect[i] will be set to newElem
//returns: i, as above
ex3 : isSubstring
Pre/post descriptions should be short and straight to the point
//returns: true iff there exists a (possibly empty) string A and B such that A word B = text
specifying derivations
derived classes inherit not only interface signatures
Makes sense to foc all the fields in the derived classes
CheapAccount : public Account virtual void bill()
//Bill()
//modifies: this->balance, this->minutes
//ensures:
minutes = 0;
balance = balance@pree + fee + rate*(max(minutes - freeminutes, 0))
derived classes
ensures is required for derived classes, but other fies
interface specification
what are the conforming implementations
- requires: (exists i: vec[i] == val) //always true returns: vec[j] == val) ? j : -1
- returns: (exists j: vec[j] == val) ? j : -1
returns: (exists j: vec[j] == val) ? j : vec.size()
returns: (exists j: vec[j] == val) ? j : -(j < 0 or j > vec.size())
returns: (exists i: vec[i] == val) ? smallest i : -1
impl1 : a
int find (const vector<int> &vec, int val){
for (int i - 0;; i++){
if (vec[i]==val) return i;
}
}
impl2 : a, b, not c (doens’t return size) , d,
int find (const vector<int> &vec, int val){
for (int i = 0;; i++){
if (vec[i]==val) return i;
}
return -1;
}
impl3: a, c, d, not e
int find (const vector<int> &vec, int val){
for (int i = vec.size() -1; i >= 0; i++){
if (vec[i]==val) return i;
}
return vec.size()
}
how precise to specify ??
- sufficiently restrictive (so that all implementations must be correct)
- sufficiently general (so that you’re not ruling out correct implementations)
= acceptable solutions
specificand set \(\subseteq\) acceptable solutions
comparing specifications
A is weaker (less restrictive)
Require B \(\Rightarrow\) Requires A
A’s postconditions are equal or stronger than B’s postconditions
Require B \(\Rightarrow\) (Ensures A and Requires A) \(\Rightarrow\) (ensures B and returns B)
checking preconditions
The client needs to uphold these
Which is okay, because these requirements are part of the interface
Best practice: have some checks of the preconditions if it’s constant time, throw assertion failure or exception if not satisfied
oop design principles
Characteristics, properties and advice for making decisions that improve the modularity of the design
OOP Basics
- Separation of Concerns
- Encapsulate what is likely to change
- Encapsulate Data Representation
- Abstraction (interfaces, ADTs)
- Reuse (through composition, inheritance)
- Polymorphism
OO Principles
- Program to an Interface, not an Implementation, aka Open Closed Principle
- Favour Composition over Inheritance
- Single Responsibility Principle
- Liskov Substitutability Principle
- Principle of Least Knowledge (Law of Demeter)
oop design principles: coupling and cohesion
coupling
Coupling is the degree to which two modules are interconnected (have to know about each other)
high coupling:
- modules that affect each other’s control flow
- components of the module communicate via global variables and/or they contain/use each other directly. (aka highly dependent on everything)
mid-ish coupling
- components in modules communicate via function calls or passing aggregate types or arrays
low coupling
- modules communicate only via public interface passing basic data types, don’t have to know about other class or some structure of another class
We desire low coupling, because otherwise changes to one module are more likely to cause mandatory changes in another.
cohesion
to what degree is an individual module (header + implementation) specifically focused on a goal
high cohesion
- components of the module work together to complete one specific goal
- i.e. std::vector (the only pieces in vector are to make vector work)
mid-ish cohesion
- components of the module are connected in what they do, or how they do it, but achieve possibly distinct tasks
- i.e. std::algorithm (i.e. many share common code, work on iterators… but do different tasks)
low cohesion
- components of a module are connected by basically nothing, is a jumble of tasks
- i.e. std::utility has a whole bunch of small useful things
We want high cohesion, strictly because it makes modules more manageable. i.e. knowing where to look to make a change, or to find a bug
oop design principles: open closed principle
principle: a module should be open for extension but closed for modification
AKA program to an interface, define and give it to the clients, and the clients can extend it
approach to extend code
Have client code depend on an abstract class (that can be extended) rather than on concrete classes, as seen below)
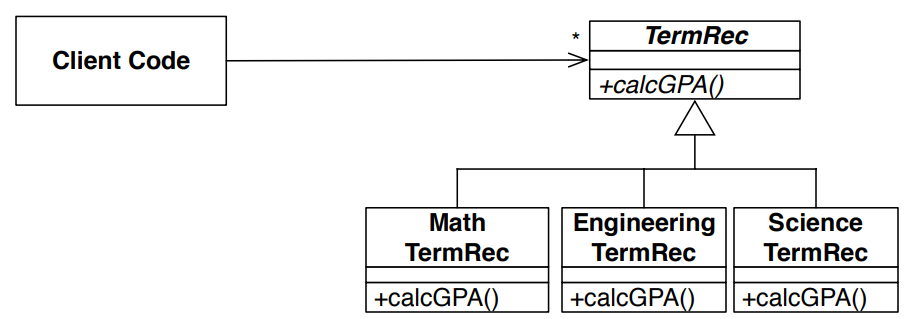
Abstract base class may provide a default implementation that the derived classes may override (declare and define common data and operations)
interface vs. implementation
The abstract base class designer determines what parts of a member function the derived class inherits:
- interface (declaration) of member function e.g. printStats
- interface and (default) overridable implementation e.g. calcGPA
- interface and non-overridable implementation e.g. print
class TermRecord {
public:
virtual void printStats() const = 0;//template method op
virtual float calcGPA(); //compute mean average
void print() const; //print template transcript
...
};
class MathTermRecord : public TermRecord { ... }
class EngineeringTermRecord : public TermRecord { ... }
inheritance vs. composition
Problem: When defining a new class that includes attributes and capabilities of an existing class, should our new class:
- inherit from the existing class (inheritance)? i.e. Window is a Rectangle with height and width
- include existing class as a complex attribute (composition)? i.e. Window has a Rectangle with height and width
Favour inheritance:
- when using sub-typing, i.e. using the fact that a derived class can be used wherever the base class is accepted, a MathTermRecord is a TermRecord, an EngTermRecord is a TermRecord
- using the entire interface of an existing class
Favour composition:
- for simple (non-overriding) code reuse and extension (because with composition, the components’ capabilities aka data and functions can change at run-time) i.e. usages of Rectangle vary by context
Window should be composition (owns-a), because when Window is deleted, the associated Rectangle (WindowImpl) should also be deleted because there are no relevant use cases
delegation
Delegation in object composition simulates inheritance-based method reuse:
- Composite object delegates operations to component object.
- Can pass itself as parameter, to let delegated operation refer to composite object.
i.e.: Window needs to calculate its area. It delegates this calculation to Rectangle.
area() { return rectangle->area()is a member function of Window- Rectangle has a member function
area(){ return width*height; }
Follow NVI
LSP
maintain no more,
weaken no les
pre \(\Rightarrow\) pre pre_based && post_derived \(\Rightarrow\) post_base
void stack::push(int n) {
vec.emplace_back(n);
}
void bounded_stack::push(int n){
if (vec.size() >= cap) throw stackFull {}
vec.emplace_back(n);
}
Rob’s nitpick on word:
parameters: are variables in a method’s signature
arguments: are data that get passed in the method’s parameters when the method is called, the actual value of this variable
Is ChequingAccount (with a credit limit) substitutable for Account?
No, mainbalance can be greater than these two
We want to make account more general
encapsulation of components
Information Hiding: Modular design should hide design and implementation details, including information about components.
All the logic that relates to one component, be wrapped in that component (not in base class)
If you can’t g
If you give them protected setters,
and the setters have code to maintain invariants
and follow NVI, such that all our virtual functions should also be non-public
ClientCodeLeft
t->addTermRecord("Spring2018")
t->computeTermGPA("Spring2018")
t->printTermRecord("Spring2018")
ClientCodeRight (bad)
Transcript *t;
TermRecord *tr;
...
tr = t->getTermRecord("Spring2018");
tr->computeGPA();
tr->print();
in general, we dont like to return pointers to our fields client s
void Store::settlebill(float total) {
Customer->getPayPal()->getCreditCard()->charge(total);
//we give clietn a settle bill method
But still non-ideal, because paypal should know its methods
we shouldn’t
the component interface should do all the work
which leads us to the Law of Demeter
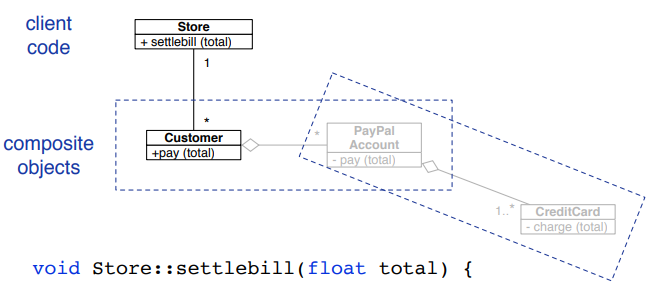
law of demeter
“Law” tests encapsulation: an object “talks only to its neighbours”
if m2 returned an f m1 can talk to b,c and d and m2 should talk to c and d
aka:
- You can play with yourself.
- You can play with your own toys (but you can’t take them apart),
- You can play with toys that were given to you.
- You can play with toys you’ve made yourself.
But:
- not really a law
- you shouldnt be breaking your back to follow the law of demeter (says Rob).
example, is this substitutable??
For every min over 200 a month, it’s an extra $1. BasicAccount::call() creates a record of a cellphone call, recording the start date and start time of the call and the duration in minutes. BasicAccount:bill() decrements the account’s balance by the monthly service fee ($100). BasicAccount::pay() increments the balance by the amount paid.
CheapAccount::call() creates a record of a cellphone call, and updates the number of minutes (numMinutes) of calls in the current month. CheapAccount:bill() decrements the account’s balance by the $30 monthly service fee and by $1 for each minute of calls beyond the free 200 minutes of calls in the current month; it also resets numMinutes to 0 to start recording number of call minutes for the next month.
Are the signatures matching?? (i.e. types) yes
Are derived methods promising less?? or requiring more??? no, they both promise that the account are charged the correct amount
 to be:
to be:
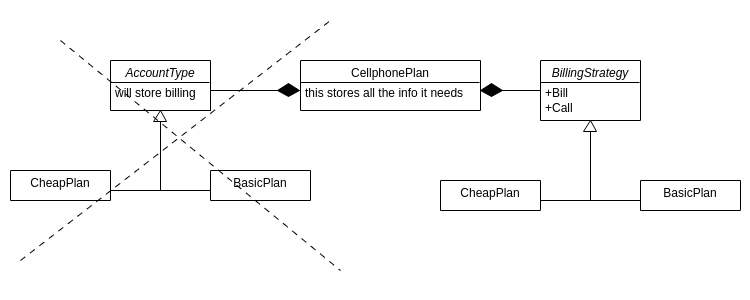
line 21: issue, it’s calling the output operator for item->startDate, item->endDate
Just overload the output operator for a callRecord(), for line21-22 to be std::cout << *obj << endl; instead of the client manually printing the fields.
double dispatch (the visitor pattern)
problem statement
we want a function that runs depending on the type of 2 objectS:
i.e. you’re creating a video game:
- Enemies (turtles, bullets)
- Weapons(stick, rock)
So we want something :
virtual void attack(Weapon &w, Enemy &e);
But we can only place the virtual function in one class. If we put it in weapon, the actual function dispatches based on Weapon, but not Enemy.
Vice versa if we put it in Enemy.
solution
Combine overloads and overrides to achieve the desired behaviour
class Enemy {
public:
virtual void beStruckBy(Weapon &w) = 0;
}
class Turtle: public Enemy {
public:
void beStruckBy(Weapon &w) override {w.strike(*this);}
}
class Bullet: public Enemy {
public:
void beStruckBy(Weapon &w) override {w.strike(*this);}
}
Note that they are different: *this is i.e. a Turtle reference, specifically not a Bullet reference.
class Weapon {
public:
virtual void strike(Turtle& t) = 0;
virtual void strike(Bullet& b) = 0;
}
class Stick : public Weapon {
public:
void strike(Turtle& t){
/*code to strike TURTLE with Stick*/
}
void strike(Bullet& b){
/*code to strike BULLET with Stick*/
}
}
//Rock is the same as Stick
class Rock : public Weapon { ... }
Client usage:
Enemy &e = ...;
Weapon &w = ...;
e.beStruckBy(w);
Steps:
- Appropriate
beStruckBy()is called based on the actual type of enemy (virtual dispatch from e) beStruckBy()callsw.strike(*this)which virtual dispatch calls the appropriatestrike()method, based on the overload.- Virtual dispatch means the correct strike based on weapon type gets called.
visitor pattern’s flaw
The visitor, which in this case is the Weapon classes, is HIGHLy coupled to the Enemy class.
If we want to add new types of enemies, we need more strike methods for the new enemies.
We agree that it should be highly coupled
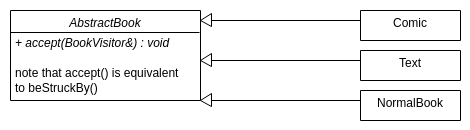
Add functionality in a class for the whole hierarchy without ..????
that is breaking the single responsibility rule
class AbstractBook {
string title, author;
int numPages;
public:
virtual void accept(BankVisitor&) = 0; //beStruckBy() equiv
}
class Comic: public AbstractBook {
public:
void accept(BankVisitor&v) override {
v.visit(*this);
}
}
//similarly for Text and Comic
class BookVisitor {
public:
virtual void visit(Text& t) = 0; //strike()
virtual void visit(NormalBook& b) = 0; //strike()
virtual void visit(Comic& c) = 0; //strike()
}
we want a catalogue that keeps track of how many Books we have for each:
- Author (if normalBook)
- Hero (if Comic Book)
- Topic (if Text Book)
#include <unordered_map>
#include <map>
using namespace std;
class Catalogue : public BookVisitor {
unordered_map<string, int> theCatalogue;
public:
void visit(Comic& c) override {
++theCatalogue[c.getHero()];
}
void visit(Text& t) override {
++theCatalogue[t.getTopic()];
}
void visit(NormalBook& b) override {
++theCatalogue[b.getAuthor()];
}
}
Note that the index operator [] used on stl::map will return the value if it exists, otherwise it will add that key and default init the value (default construct if its an object, or zero our the bits if its a POD)
virtual NormalBook& AbstractBook::operator=(NormalBook&);
Sometimes you need a value to be treated like another type, or more commonly, treated like the type it actually is. To achieve this we use casts.
In general casts should be avoided (because they are often indicative of bad design). If you must cast, you should use the c++ cast, NOT the c-style cast.
//c_style casts
int* p ...
void* v = (void*) p;
book* b = (book*) v;
// aka can cast anything
//c++ casts
//doesn't let you cast everything
c++ cast
static_cast:
for sensitive casts with well-defined behaviour
float x = 4.5f;
int y = static_cast<int>(x);
Also casts from base class pointers to derived pointers. Dangerous, you’re telling the compiler to trust your cast, that pointer actually points to the object that I say it does.
Comic c ...;
AbstractBook *pb = &c;
static_cast<Comic*>(pb);
Rip partial assignment and more.
reinterpret_cast
Student *s = new Student("Harry");
Turtle *t = reinterpret_cast<Turtle*>(s); //is undefined behaviour
Weapon *w = new Stick;
w->strike(*t); //error
const_cast
for casting away const behaviour, should NOT be used to modify const objects. Should only use when you know casting it still won’t modify the value.
i.e. working with a library that you don’t own, a function takes in a non_const parameter, but you know it doesn’t modify the const promise.
// not your code but you know it doesn't modify the Foo
void doSomething(Foo *p);
// client code (your code):
const Foo *p;
doSomething(*p); //Error, doesn't work
doSomething(const_cast<Foo*>(p)); //ah yes
dynamic_cast
is for casting pointers of references that are to a base class, down to a derived class pointer or reference
Attempts the cast, if the object the pointer points at is not actually of that derived class (the type you’re trying to cast to), then it returns the nullptr instead.
This following code is valid:
void WhatIsIt(AbstractBook *pb){
if (dynamic_cast<Comic*>(pb)){ //nullptr returns false
cout << "tis a comic" << endl;
}
if (dynamic_cast<Text*>(pb)){ //nullptr returns false
cout << "tis a textbook" << endl;
}
if (dynamic_cast<Comic*>(pb)){ //nullptr returns false
cout << "tis a comic" << endl;
}
// this is not polymorphism
// this code is HIGHLY coupled to the book hierarchy, and
// defeats the purpose of having a hierarchy
}
But, what if a cast is a reference? and what if it fails
i.e.
NormalBook b{ ... };
AbstractBook &r = b;
Comic &c = dynamic_cast<Comic&>(r); //obviously fails
It throws an exception, of std::bad_cast (perhaps).
With dynamic cast, we could finally (if we wanted to) provide a polymorphic assignment operator, but I still suggest you disallow the client fro assignment through base class ptrs.
class AbstractBook {
string title, author;
int numpages;
public:
virtual AbstractBook& operator=(const AbstractBook& b){
title = b.title;
author = b.author;
numpages = b.numpages;
}
}
//this is how you would do it, if you need assignment between different
class Comic: public AbstractBook{
string hero;
public:
Comic& operator=(const AbstractBook& b){
Comic &other = dynamic_cast<Comic&>(b);
//throws if not actually a comic (mixed assignment)
Book operator=(b);
hero = Other.hero;
return *this;
}
}
Dynamic cast only works if the compiler can figure out what the actual type of an object is. (i.e. virtual dispatch, gotta figure out what the object is)
Dynamic cast only works on types that have at least one virtual function (and hence a vtable).
side note: how are virtual functions implemented by the compiler??
How do virtual functions really work?
- in order for the compiler to call the correct virtual function, it needs additional information.
struct A {
virtual void hello() { cout << "im an A" << endl; }
};
struct B {
void hello() { cout << "im an B" << endl; }
//overwritten A's hello()
};
int main(){
A* ap;
char c;
cin >> c;
if (c < 'c') ap = new A;
else ap = new B;
ap->hello(); //what does this program print?
}
Note that if the user inputs a char that is less than ‘c’ in the ascii table, then it prints, im an A. Otherwise, it prints “im a B”, (if ignoring the fact that a read will fail and own garbage).
How does the compiler achieve this??
Recall that a function call is just pushing appropriate data onto the stack and then jalr (jump and link, changes the program counter to another place, store the location so that we can return when we pop the stack frame).
This works fine for non-virtual methods or standalone methods.
If A::hello was non-virtual, then at the line ap->hello(), the compiler goes to the definition of the function and knows exactly where to go. So since hello() is virtual, how does the compiler know where to jump on ap->hello()??
Can’t be based on input, because compilation happens before the program is run, so the decision of which method to call is made at the step of creating the object ap.
Well luckily, of course at the point of object creation, the compiler knows what type of object it is creating. While at ap->hello() where it has no idea what ap actually points at.
So the compiler at the point of object creation leaves itself a trail of breadcrumbs. What it does is store a pointer as the first sizeof(ptr) (system dependent, but 8) bytes of each object (from a class with virtual methods)*
* the standard doesn’t specify how virtual methods must behave: the implementation is up to the compiler. But virtually all compilers implement it this way.
The pointer it stores is called the virtual function table pointer, which is a pointer that points to a table of function pointers to the implementations of the virtual methods of that class.
Note that each class wit virtual methods has one table. Each object of the same type thus shares the same table/has the exact same pointer.
struct A {
int x;
virtual void hello() {...}
virtual void boo() { ... }
}
struct B {
int y;
virtual void hello() {...}
virtual void boo() { ... }
}
Client code:
A a;
B b;
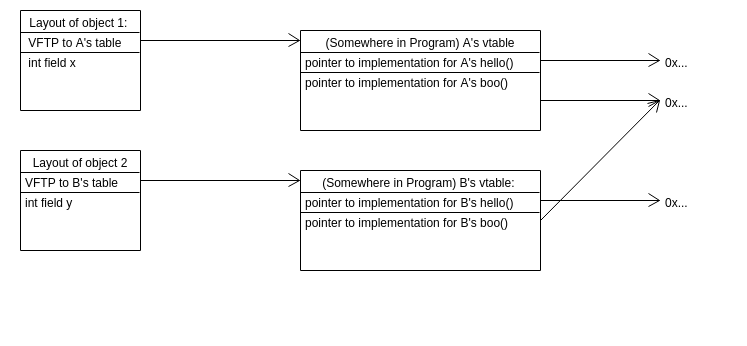
So now, when the compiler sees ap->hello(), it knows where to jal. It’ll access the table via the pointer stored in the first bytes of the object, and then read the offset in the table to find out the offset for the desired function, and jal to that location.
i.e.
Undefined behaviour:
A a1;
A a2;
B b;
int **pa1 = reinterpret_cast<int**>(&a1)
//dereferencing *pa1 gives you the pointer to an int, which is the first 8 bytes of the a object, which is the pointer to the virtual function vtable
int **pa2 = reinterpret_cast<int**>(&a2)
cout << *pa1 << endl;
cout << *pa2 << endl;
// instances of same object share the same pointer to vtable
//same print
//manually call A.hello() and B.hello(), using information stolen from vtable.
//g++ looks for the *this pointer, breaks. but clang++ compiles the next two lines
reinterpret_cast<void(*)()>(**pa1)()
//cast it as a function pointer, of return type void with no parameters, and call that function
//im an a
reinterpret_cast<void(*)()>(**pb1)()
//cast it as a function pointer, of return type void with no parameters, and call that function
//im a b
//overwrite the first 8 bytes of
//which assigns A's vtable to B's vtable
*pa1 = *pa2
reinterpret_cast<A*>(pa1)->hello() //should print im a B, because of virtual dispatch
//but compiler cache knows that it's an A, doesn't do
a1.hello()
//im an A
(&a1)->hello()
//im a B
//changed the identity of the a1 object
multiple inheritance
In OOP, it is often the case that our classes may support a variety of interfaces
For example, consider you’re making a video game and you want an interface that specifies which objects are “drawable”.
class Drawable {
Renderer &r;
public:
void draw(int x, int y) = 0;
};
now every entity that is drawable will inherit from Drawable.
class Controllable {
Renderer &r;
public:
void draw(int x, int y) = 0;
};
This situation of multiple inheritance is an issue.
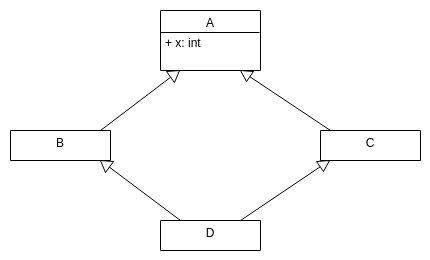
Does this receive two A? yes. It’s a compilation error.
i.e.
D obj;
obj.x; //what am i referring to here??
This is ambiguous. Class D has two x because it has two A objects effectively, one inherited from B and one from C.
We can specify which one you want:
obj.B::x = 5;
obj.C::x = 10;
cout << obj.B::x; //prints 5, x are distinct variables
This is called the deadly diamond problem, and also known as the diamond of death problem, or the deadly diamond of death problem.
C++ solves this problem with virtual inheritance
virtual inheritance
class A {
public:
int x;
}
class b : public virtual A {
}
class C : public virtual A {
}
class D : public B, public C {
}
But this makes our result very strange.
The first result is that it fixes our problem.
i.e.
D obj;
obj.x; //no longer a problem because D has only one X
How does the compiler achieve this?
Before multiple inheritance, if you looked at the beginning address of an object, it looked like any of its ancestors:
Uses sizeof() to cover the object (oldest grandparent … all the way to youngest child)
Then, for multiple inheritance:
For multiple virtual inheritance, the metadata stored in object layout has multiple vtables to tell you offsets, then this can look like any of these objects.

Consider we want to find the A fields of this object, while it is pointed at by a B pointer. What are the possibilities?
The distance to the A fields through a B ptr is not knowable at compile time, just as its not knowable at compile time which virtual method to call.
Use vptr to jump to other objects’ vptr, which uses that information to virtual dispatch.
refactoring
- rewrite previous code, sort of
- make changes to the internal structure of the code (without changing the externally visible behaviour)
- does not count bug fixes, new feature additions, changes to public interfaces
- instead of changes made to reduce complexity of current design and facilitate future changes
what should be refactored
- Bad Smells, indications of bad design
- overly complicated code
- overly coupled code
In general, anything that will make future changes harder
when should one refactor??
In general, easiest done early on, in case the software grows too large and the components that need to be refactored grow to take a huge amount of time…
When going in to make another change, if you identify a bad smell, you should fix that first, since it will probably make your change easier as well
However, don’t spin your wells forever over designing your code in the first place:
- can’t account for everything, accept that code will have to be refactored early and often
- can lead to over-engineering, which itself complicates the code
when should one not refactor??
When refactoring would break other large components or your fellow engineers’ mental model of the code needed to do their work
Don’t bother refactoring prototypes: they should usually be thrown out anyways.
Don’t refactor when you’ve got a deadline you need to meet: suck it up, accept the bad code and make it work. But this exact practice of just making it work at the cost of complicating /messing up your code base is known as incurring a “technical debt”. Aka you’re taking out a “loan” by using the quick and dirty solution, such that it needs to be repaired with future refactoring to bring your code bases quality back to a point where changes aren’t overly costly on engineering hours.
rule of 3
-
the 1st time that you do a bad thing, just do it
-
the 2nd time that you do a bad thing, wince and do it again
-
the 3rd time that you do a bad thing, refactor or consider refactoring it soon
the stl algorithm library
is a collection of useful template functions that implement common algorithms mostly operating on iterators
i.e.
template <typename Iter, typename Fn>
void for_each(Iter &begin, Iter &end, Fn f){
while (begin != end){
f(*begin);
++begin;
}
}
void print(int n ){ cout << n << " "; }
int main() {
int a[] = {1,2,3,4,5}
for_each(a.begin(), a.end(), print);
//prints 1 2 3 4 5
}
template<type inIter, typename outIter, typename Fn>
outIter copy_if(inIter begin, inIter fin, outIter dest, Fn f){
//copy content from range [begin, fin) to dest
while (begin != fin){
if (f(*begin)){
*dest = *begin;
++dest;
}
++begin;
}
}
copy_if assumes that dest has enough space, so you must allocate and make sure of this
client code:
vector<int> v{4,8,12,13,14,15};
vector<int> w(v.size());
copy_if(v.begin(), v.end(), w.begin(), ...)
needs a fn that takes in a type int, which can be implicitly cast
and returns a type that is implicitly cast-able to a bool
seems like an awfully large amount of code to declare, for a single line of client code to use..
presenting the lambda function
lambda functions in c++
a lambda \(\lambda\) function is known as an anonymous function, because it is a function without a name.
effectively, it’s a way to write a function literal, much like how we can write integer literals:
[] () param_list { function body }
about lambda functions
- the
[]is th lambda specifier, or capture clause - the
param_listis optional, if the compiler can deduce the return type - no variables (not even globals) are accessible in the lambda’s body’s score, unless you capture them with the capture clause
int n = S;
vector<int> v{7,2,8,9};
vector<int> w(v.size());
copy_if(v.begin(), v.end(), w.begin(),[](int q) {return q >n; }) //but n is inaccessible
copy_if(v.begin(), v.end(), w.begin(),[n](int q) { return q >n; }) //this is ok
capture clause syntax
[n]creates a local copy of n[&n]creates a ref of n-
[z, &n]creates a local copy of z, as well as captures a reference of n [=]captures everything in scope that you use in the function body, by value-
[=, &n]as above except for n, which it captures by reference [&]captures everything in scope that you use in the function body, by reference[&, n]same as above, except for n which is captured by value
lambdas are great if you want one off function that you only need once But if you want a family of functions, there may be a better choice
Consider the transform() function:
vector<int> v{1,2,3,4};
transform(v.begin(), v.end(), [](int n){ return n++; })
// v = {2,3,4,5}
template <typename Iter, typename Func fn>
transform(Iter beg, Iter fin, Func fn){
//applies fn to everything in [beg, fin)
//assigns those values to return result
}
What if we wanted to do +2 instead, to each element? What if this operation but with differing values added is something we want to do often??
What things can be supplied as type Func??
- anything that can be callable as a function, that is of the same type as the dereferenced iterator,
Type requirements for transform():
- callable as a function
- single
- return a type
What is callable as a function?
- functions
- objects of a type which have had the function call operator overloaded
- i.e.
class Addn{ public: Addn(int n): n{n}{} int operator()(int q){ returns q+n;} } - the way that this can be used, is to create an Addn object, and you can take that object and call it as you would call functions
Addn plus5{5}; cout << plus5(2) << endl; //prints 7 Addn sub3{-3}; cout << sub5 << endl; //-1
- i.e.
Hence, the solution to being able to do the same operation multiple time:
vector<int> v{1,2,3,4};
transform(v.begin, v.end(), Addn{10});
//v = {11, 12, 13, 14}
side note on callable objects as functions
In functional programming, you want to have pure functions without state. But with objects that are callable like functions, you can store a state.
We can use function objects to create functions with state:
class IncreasingPlus{
int n;
public:
IncreasingPlus(int n) : n{n} {}
int operator() (int q) {return a + n++; } //postfix increment is intentional here
}
client code:
vector<int> w{1,2,3,4};
transform(w.begin(), w.end(), IncreasingPlus{1});
//w = {2,4,6,8} 1 + 1, 2 + 2, 3 + 3, 4 + 4
accumulate()
In the <numeric> header, there is a function called std::accumulate
This function, depending on its parameters, allows us to implement what is known as foldr and foldl.
foldr and foldl
higher order functions that can be used to represent more-or-less higher order
that can do recursion on arbitrary containers
template<typename Iter, typename T, typename Func>
T accumulate(Iter beg, Iter end, T base, Func fn);
accumulate() must have two param:
- one that takes a T
- one that takes a return type of *Iter
accumulate() must return a T
accumulate() does:
f(f(f(base, *begin) *begin + 1) *begin + 2) ...
Recursively calls f on the return value of the previous f application, and the next thing in the container.
why is it powerful
Can achieve complex tasks in very little lines.
#include <iostream>
#include <numeric> //std::accumulate
#include <algorithm>
int main(){
vector<int> v{20,15,-2,0,5};
accumulate(v.begin(), v.end(), 0, [](int n, int p) { return n+p; }); //returns sum of vector, 38
accumulate(v.begin(), v.end(), 0, [](int n, int p) { return n*p; }); //returns prod of vector, 38
accumulate(v.begin(), v.end(), 0, [](int n, int p) { return n-p; });
//note that this isn't cumulative, should get different results with rbegin and rend
accumulate(v.rbegin(), v.rend(), 0, [](int n, int p) { return n-p; });
string s{"1101"}; //13
accumulate(v.begin(), v.end(), 0, [](int n, char c) {
return (c=='1') ? 2*n + 1: 2*n;
}); //this converts a binary string into an integer
}
for s = 1101
function takes in the base. The operations should be commutative. Note that the base or the return result is the left-hand result.
foldl: when your first 1 gets multiplied the most, base most is the 0th index as the leaf, read string s as 1101
foldr: when your nth-index 1 starts, read string s as 1011
vector<int> v {1,2,3,4}
vector<int> w;
for_each (v.begin(), v.end(), [&w](int n) { if(!(n%2) w.emplace_back(n))})
// this is basically a range for loop, or a copy_if
// but we didn't have to reserve the size of w
what if we want to copy_if but don’t want to essentially write the copy ourselves??
or we don’t know the size we need to reserve, or don’t even need to know the size of w…
attempt 1: use this silly function called reserve
attempt 2: back_inserter()
#include <iterator> //<--- there are some more complex iters, i.e. over a stream
vector<int> v{3,4,8,10}
vector<int> w{1,2}
//desired output: {1,2,3,4,8,10}
copy(v.begin(), v.end(), back_inserter(w))
Note that the back inserter allocates more space as necessary, we don’t need to manually emplace back, and we don’t need to manually reserve more space
what if we want to sort a map (this is totally unrelated to the previous content)
i.e. want to print out result by most common word to least common word, instead of sorted by key
map<string, int> theMap;
//read from cin
string s;
while(cin >> s) ++theMap[s];
//create a vector and store the pair<string, int>
// note that the return type through a map iterator is a pair<string,int>
vector<pair<string,int>> sorted;
copy(theMap.begin(), theMap.end(), back_inserter(sorted))
sort(sorted.begin(), sorted.end(), [](pair<string,int> lhs, pair<string,int> rhs){
return lhs.second > rhs.second;
});
for (auto &p : sorted){
cout << p.first << " - " << p.second << endl;
}
note that back_inserter would not work on an unordered map, because the back isn’t well defined.
the singleton (anti) pattern
taught last because it’s not a good design pattern to use in the project
there are good uses i.e. if you want to connect to an embedded system socket once idk (it breaks down on multithreading anways) (there are better ways to do this anyways smh)
“The singleton pattern is an anti-pattern” —Bjarne Stroustrup
basically, you use a global variable, and have every. what could go wrong??? :)
many modules share the singleton, but it’s high coupling (and hence its bad)
video game example
context: there are multiple classes in your game, you need to be aware of the current settings that your user has chosen
class Settings {
//singleton class
static Settings s;
//can't store objects of the same type within themselves
//must make it static, else your object becomes infinitely huge
//a static object isn't actually stored of any object (it's global data)
//so this is ok
Settings(){}
Settings(const Settings &other) = delete;
public:
static Settings& getInstance() { return s; }
}
in Settings.cc
Settings Settings::s{};
client code
Settings &s = Settings::getInstance();
s.other_methods();
...
s.setResolution(640,480);
...
void update() {
Settings &s = settings::getInstance()
screen(s.setWidth() ...)
}
and then you forget to delete the Singleton and you get a mem leak!
side note on memory leak
a memory leak isn’t when you forget to delete, it’s when you hold but drop it midway, and then ask your OS for memory continuously. And then your OS will run out of memory, and then you either use your swap space, or your program crashes.
But if you just allocate the Settings object once, when that program ends, it’s still safe per se.
it’s only a problem when you ask your OS for memory because your program keeps asking for more memory without deleting, creating unrecoverable memory.
constexpr
the second template parameter of array is an int, but it can’t just be any int.
The int must be knowable at compile time, that means complex functions to calculate its value are out.
We’ve previously seen a way to force c++ to calculate at compile time (template meta programming)
This brings us to constexpr:
c++ has had a build in mechanism since c++ 11 for compile time computable constants, and it was made much more useable in c++14
constexpr int x = 5;
//x is a constexpr, it is knowledgeable at compile time
constexpr int fib(int n){
}
you don’t want your compiler to evaluate a function that can possibly throw during compile time.
Hence, have to promise to the compiler that it’s noexcept
now you can use the fib() function to evaluate i.e. sizes of inputs.
i.e. std::array<int, fib(10)> a; is now compileable
constexpr int fib(int n) noexcept {
if (n == 0 || n == 1) return 1;
else return fib(n-1) + fib(n-2);
}
restrictions of constexpr function parameter types
constexpr function parameter types can only be types that can be written as literals
This does not mean only built-in types: note that member functions, including constructors, can be declared to be constexpr which will, in effect, make them writeable as a literal. (a literal is a val that can be written at compile time)
i.e. constexpr Object::Object(){} is now a literal
class Point {
int x, y;
public:
constexpr Point(int x, int y) noexcept : x{x}, y{y} {}
}
when to use constexpr
some say to use constexpr as often as possible.
but constexpr is also part of the interface that you’re providing to the client. So if you ever decide to stop providing constexpr, the client code that rely on this will break.